Sparse MoE with Language Guided Routing for Multilingual Machine Translation
Xinyu Zhao ⋅ Xuxi Chen ⋅ Yu Cheng ⋅ Tianlong Chen
2024 Poster
{kind=link}
Abstract
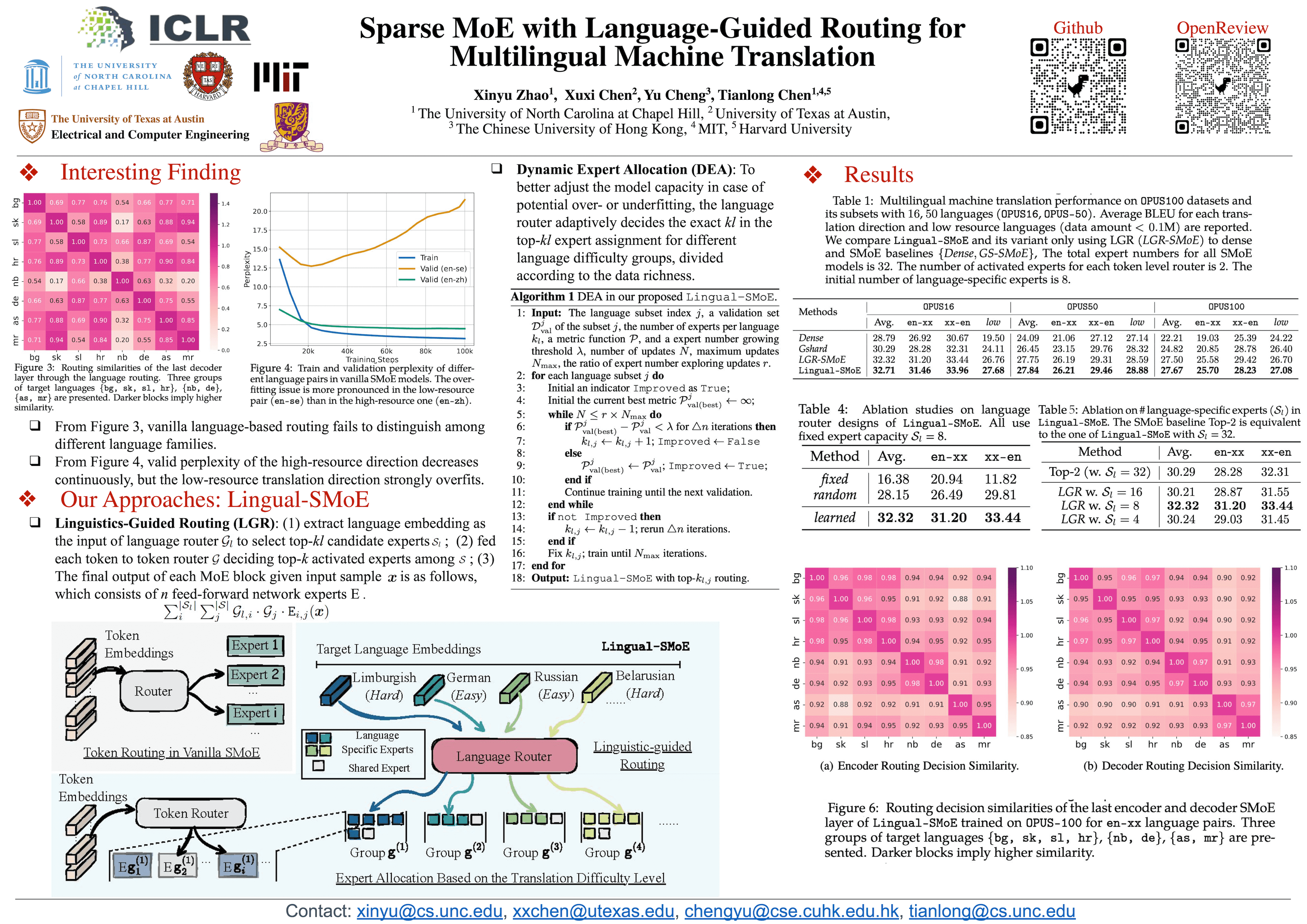
Sparse Mixture-of-Experts (SMoE) has gained increasing popularity as a promising framework for scaling up multilingual machine translation (MMT) models with negligible extra computational overheads. However, current SMoE solutions neglect the intrinsic structures of the MMT problem: ($a$) $\textit{Linguistics Hierarchy.}$ Languages are naturally grouped according to their lingual properties like genetic families, phonological characteristics, etc; ($b$) $\textit{Language Complexity.}$ The learning difficulties are varied for diverse languages due to their grammar complexity, available resources, etc. Therefore, routing a fixed number of experts (e.g., $1$ or $2$ experts in usual) only at the word level leads to inferior performance. To fill in the missing puzzle, we propose $\textbf{\texttt{Lingual-SMoE}}$ by equipping the SMoE with adaptive and linguistic-guided routing policies. Specifically, it ($1$) extracts language representations to incorporate linguistic knowledge and uses them to allocate experts into different groups; ($2$) determines the number of activated experts for each target language in an adaptive and automatic manner, according to their translation difficulties, which aims to mitigate the potential over-/under-fitting issues of learning simple/challenges translations. Sufficient experimental studies on MMT benchmarks with {$16$, $50$, $100$} language pairs and various network architectures, consistently validate the superior performance of our proposals. For instance, $\texttt{Lingual-SMoE}$ outperforms its dense counterpart by over $5\%$ BLEU scores on $\texttt{OPUS-100}$ dataset.
Video
Chat is not available.
Successful Page Load