Towards Robust and Efficient Cloud-Edge Elastic Model Adaptation via Selective Entropy Distillation
{kind=link}
Abstract
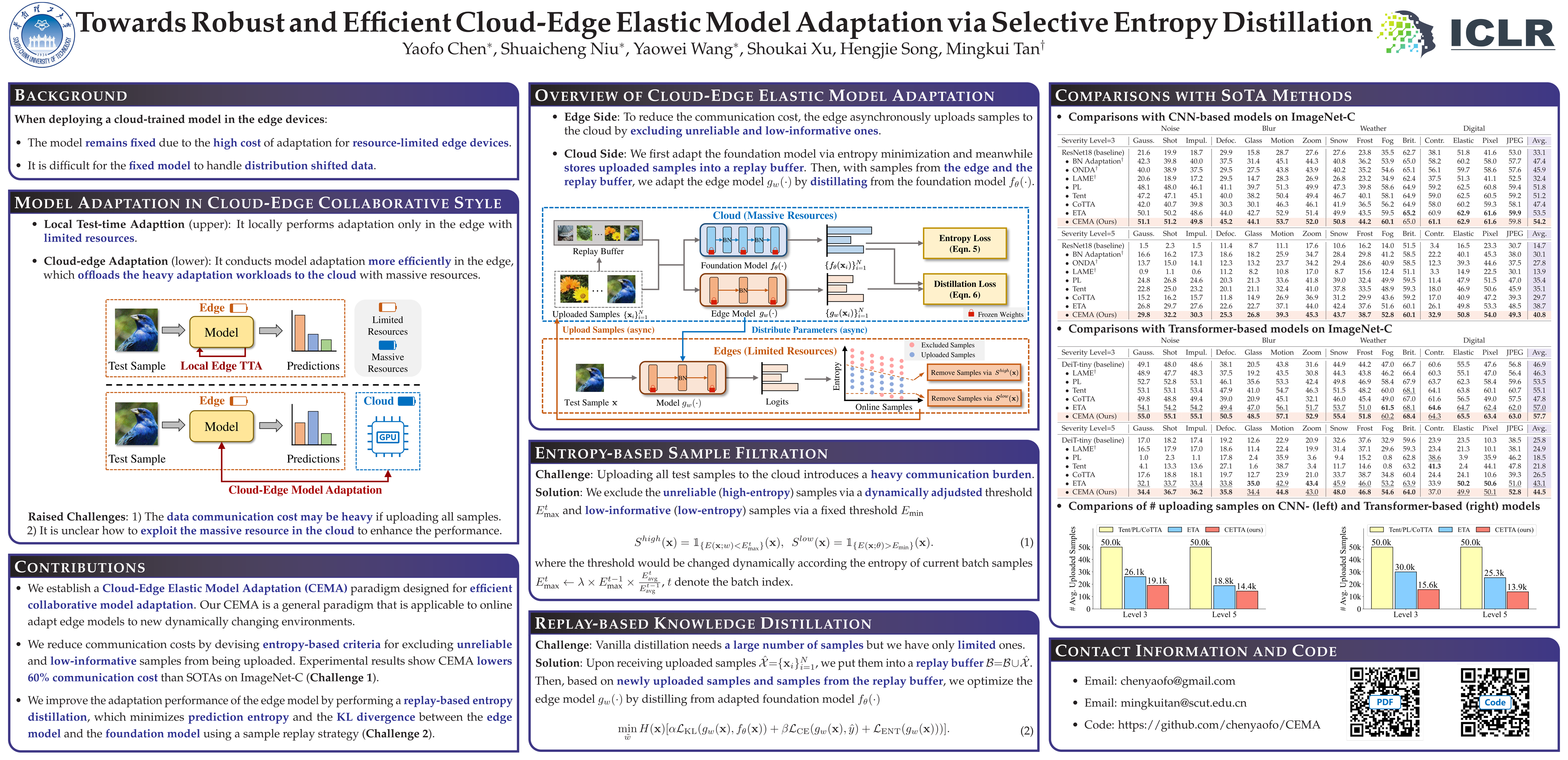
The conventional deep learning paradigm often involves training a deep model on a server and then deploying the model or its distilled ones to resource-limited edge devices. Usually, the models shall remain fixed once deployed (at least for some period) due to the potential high cost of model adaptation for both the server and edge sides. However, in many real-world scenarios, the test environments may change dynamically (known as distribution shifts), which often results in degraded performance. Thus, one has to adapt the edge models promptly to attain promising performance. Moreover, with the increasing data collected at the edge, this paradigm also fails to further adapt the cloud model for better performance. To address these, we encounter two primary challenges: 1) the edge model has limited computation power and may only support forward propagation; 2) the data transmission budget between cloud and edge devices is limited in latency-sensitive scenarios. In this paper, we establish a Cloud-Edge Elastic Model Adaptation (CEMA) paradigm in which the edge models only need to perform forward propagation and the edge models can be adapted online. In our CEMA, to reduce the communication burden, we devise two criteria to exclude unnecessary samples from uploading to the cloud, i.e., dynamic unreliable and low-informative sample exclusion. Based on the uploaded samples, we update and distribute the affine parameters of normalization layers by distilling from the stronger foundation model to the edge model with a sample replay strategy. Extensive experimental results on ImageNet-C and ImageNet-R verify the effectiveness of our CEMA.