SAS: Structured Activation Sparsification
Yusuke Sekikawa ⋅ Shingo Yashima
{kind=link}
Abstract
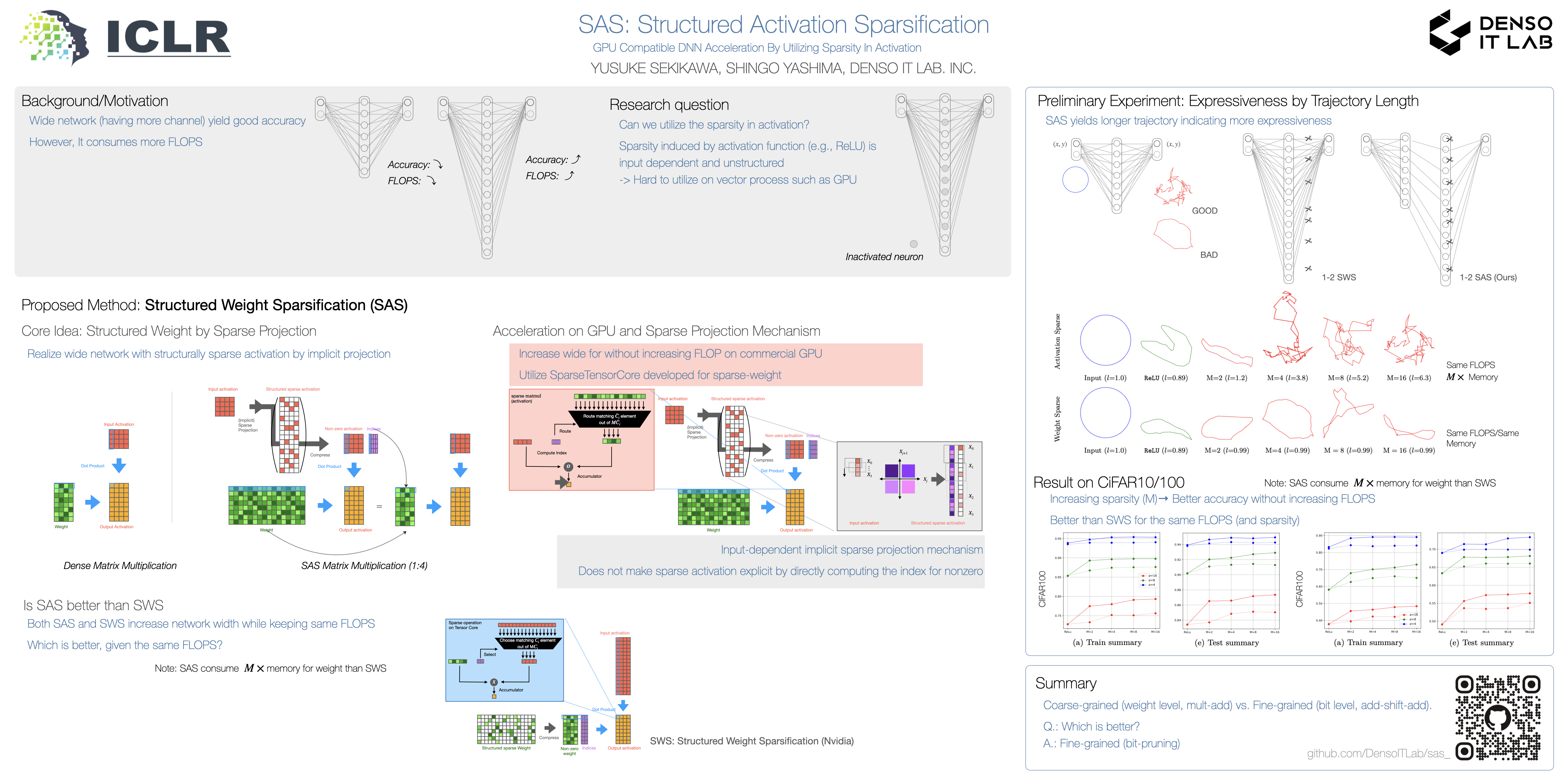
Wide networks usually yield better accuracy than their narrower counterpart at the expense of the massive $\texttt{mult}$ cost.To break this tradeoff, we advocate a novel concept of $\textit{Structured Activation Sparsification}$, dubbed SAS, which boosts accuracy without increasing computation by utilizing the projected sparsity in activation maps with a specific structure. Concretely, the projected sparse activation is allowed to have N nonzero value among M consecutive activations.Owing to the local structure in sparsity, the wide $\texttt{matmul}$ between a dense weight and the sparse activation is executed as an equivalent narrow $\texttt{matmul}$ between a dense weight and dense activation, which is compatible with NVIDIA's $\textit{SparseTensorCore}$ developed for the N:M structured sparse weight.In extensive experiments, we demonstrate that increasing sparsity monotonically improves accuracy (up to 7% on CIFAR10) without increasing the $\texttt{mult}$ count.Furthermore, we show that structured sparsification of $\textit{activation}$ scales better than that of $\textit{weight}$ given the same computational budget.
Video
Chat is not available.
Successful Page Load