Masked Structural Growth for 2x Faster Language Model Pre-training
{kind=link}
Abstract
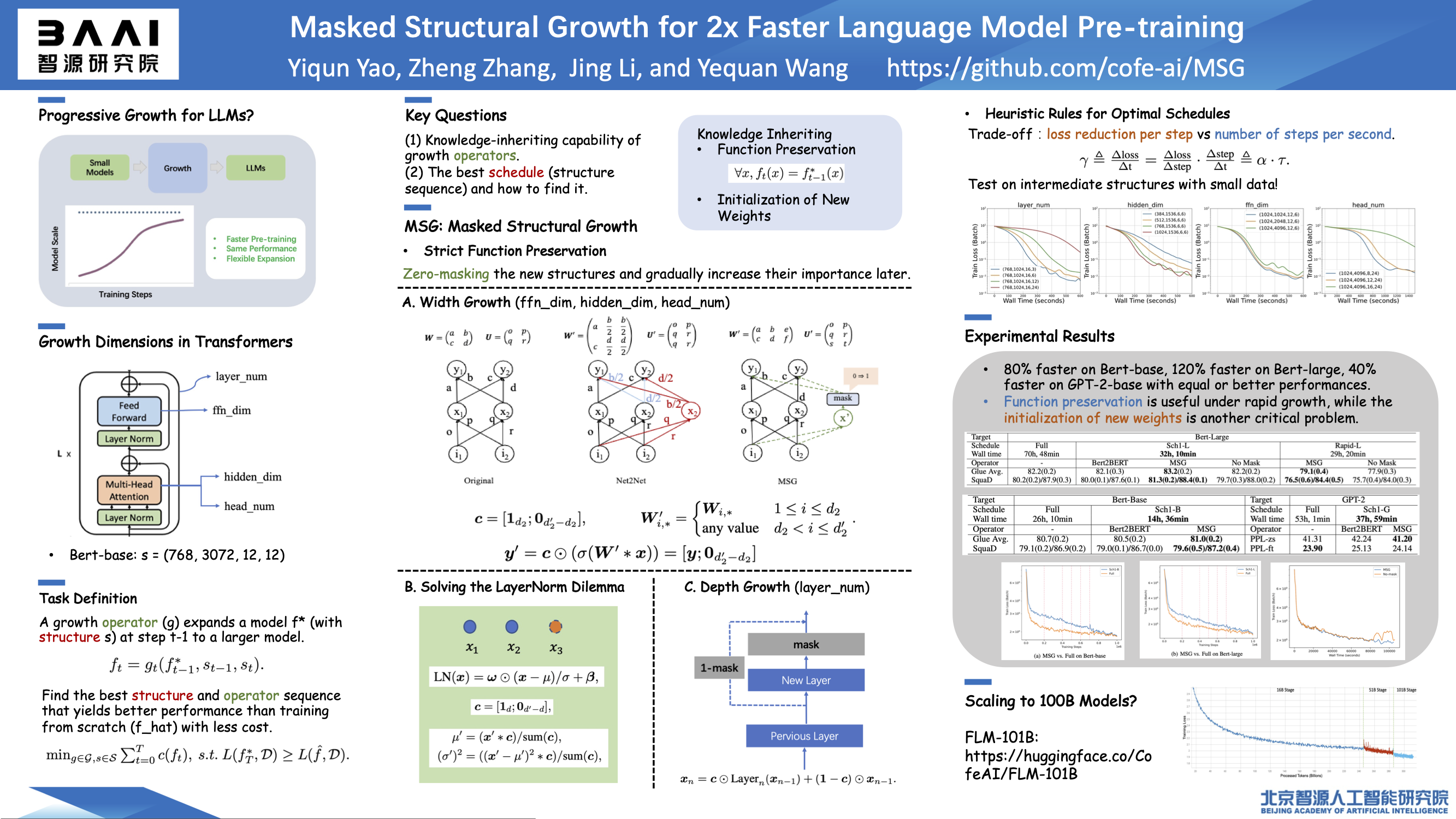
Accelerating large language model pre-training is a critical issue in present research. In this paper, we focus on speeding up pre-training by progressively growing from a small Transformer structure to a large one. There are two main research problems associated with progressive growth: determining the optimal growth schedule, and designing efficient growth operators. In terms of growth schedule, the impact of each single dimension on a schedule’s efficiency is underexplored by existing work. Regarding the growth operators, existing methods rely on the initialization of new weights to inherit knowledge, and achieve only non-strict function preservation, limiting further improvements on training dynamics. To address these issues, we propose Masked Structural Growth (MSG), including (i) growth schedules involving all possible dimensions and (ii) strictly function-preserving growth operators that is independent of the initialization of new weights. Experiments show that MSG is significantly faster than related work: we achieve up to 2.2x speedup in pre-training different types of language models while maintaining comparable or better downstream performances. Code is publicly available at https://github.com/cofe-ai/MSG.