Sampling Multimodal Distributions with the Vanilla Score: Benefits of Data-Based Initialization
{kind=link}
Abstract
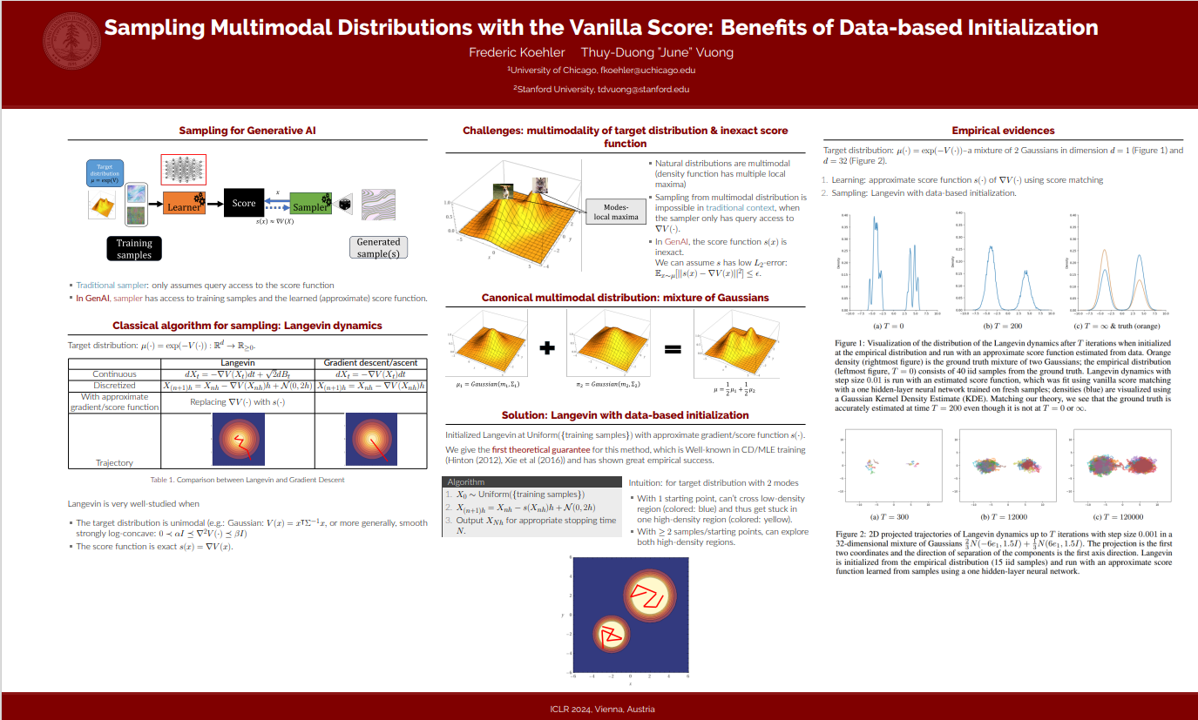
There is a long history, as well as a recent explosion of interest, in statistical and generative modeling approaches based on \emph{score functions} --- derivatives of the log-likelihood of a distribution. In seminal works, Hyv\"arinen proposed vanilla score matching as a way to learn distributions from data by computing an estimate of the score function of the underlying ground truth, and established connections between this method and established techniques like Contrastive Divergence and Pseudolikelihood estimation. It is by now well-known that vanilla score matching has significant difficulties learning multimodal distributions. Although there are various ways to overcome this difficulty, the following question has remained unanswered --- is there a natural way to sample multimodal distributions using just the vanilla score? Inspired by a long line of related experimental works, we prove that the Langevin diffusion with early stopping, initialized at the empirical distribution, and run on a score function estimated from data successfully generates natural multimodal distributions (mixtures of log-concave distributions).