ZeRO++: Extremely Efficient Collective Communication for Large Model Training
{kind=link}
Abstract
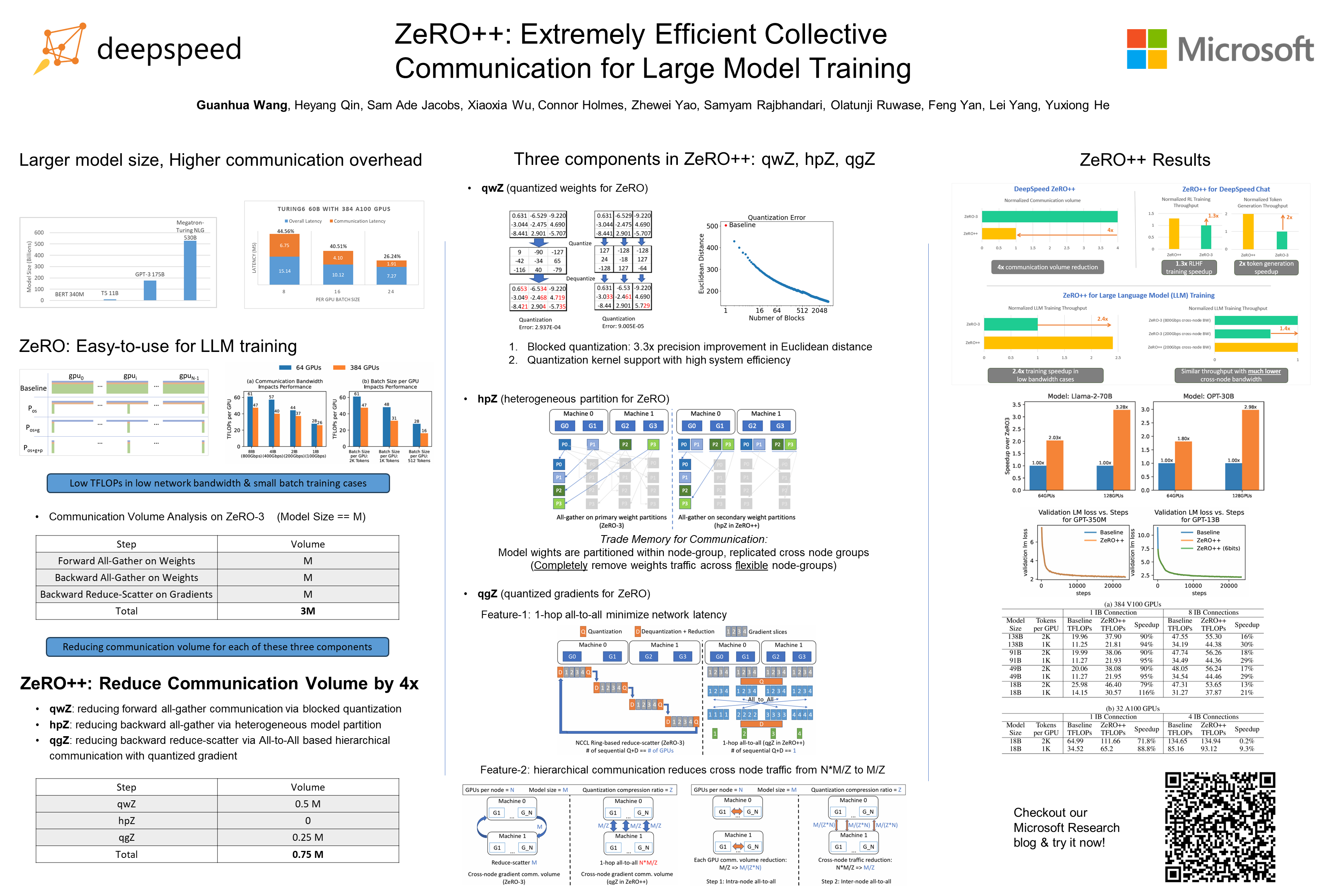
Zero Redundancy Optimizer (ZeRO) has been used to train a wide range of large language models on massive GPU clusters due to its ease of use, efficiency, and good scalability. However, when training on low-bandwidth clusters, and/or when small batch size per GPU is used, ZeRO’s effective throughput is limited due to communication overheads. To alleviate this limitation, this paper introduces ZeRO++ composing of three communication volume reduction techniques (lowprecision all-gather, data remapping, and low-precision gradient averaging) to significantly reduce the communication volume up to 4x that enables up to 2.16x better throughput at 384 GPU scale. Our results also show ZeRO++ can speedup the RLHF by 3.3x compared to vanilla ZeRO. To verify the convergence of ZeRO++, we test up to 13B model for pretraining with 8/6-bits all gather and up to 30B model for finetuning with 4/2-bits all gather, and demonstrate on-par accuracy as original ZeRO (aka standard training). As a byproduct, the model trained with ZeRO++ is naturally weight-quantized, which can be directly used for inference without post-training quantization or quantization-aware training.