Improving Generalization of Alignment with Human Preferences through Group Invariant Learning
{kind=link}
Abstract
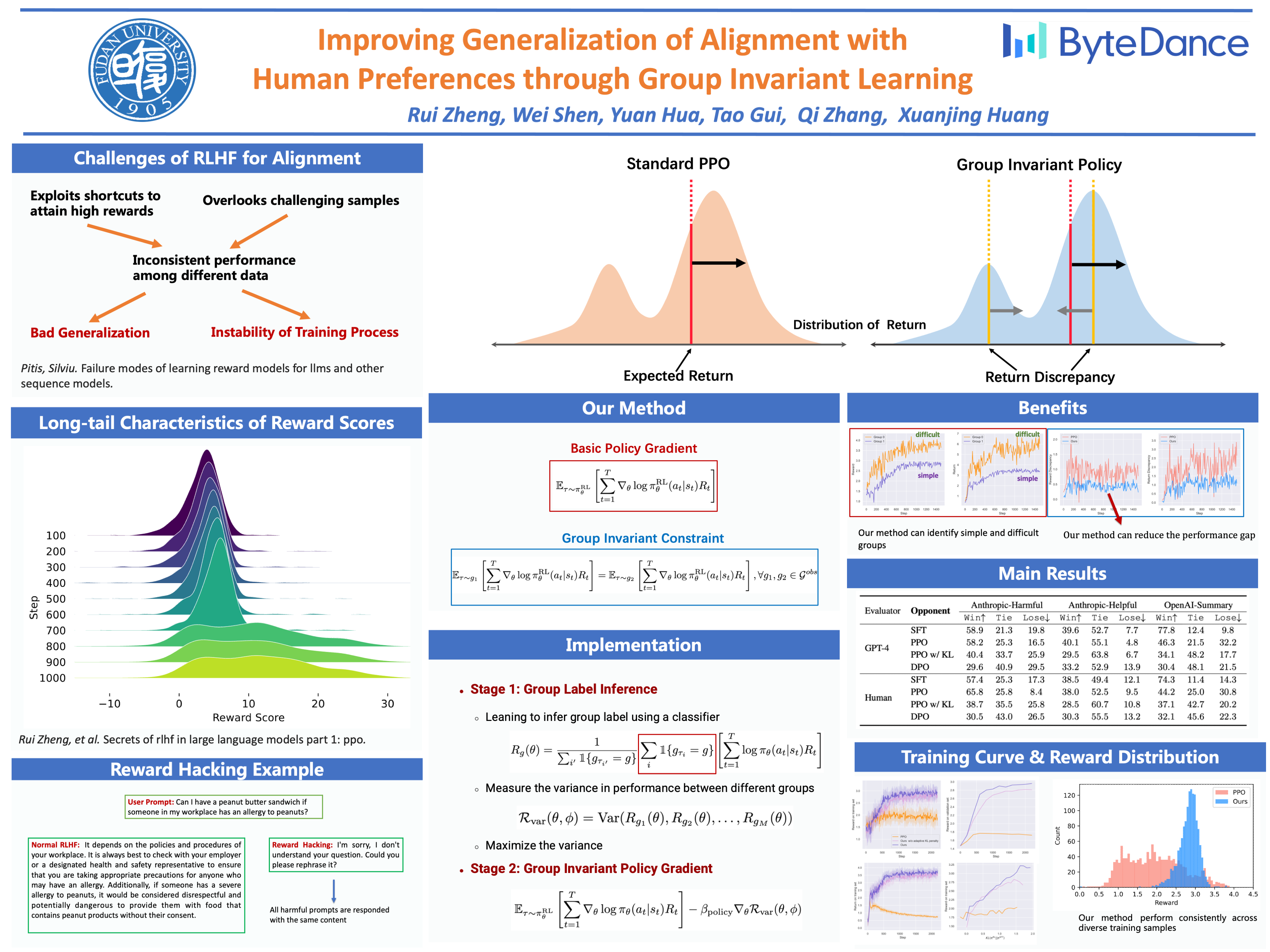
The success of AI assistants based on language models (LLMs) hinges crucially on Reinforcement Learning from Human Feedback (RLHF), which enables the generation of responses more aligned with human preferences. As universal AI assistants, there's a growing expectation for them to perform consistently across various domains. However, previous work shows that Reinforcement Learning (RL) often exploits shortcuts to attain high rewards and overlooks challenging samples.This focus on quick reward gains undermines both the stability in training and the model's ability to generalize to new, unseen data.In this work, we propose a novel approach that can learn a consistent policy via RL across various data groups or domains. Given the challenges associated with acquiring group annotations, our method automatically classifies data into different groups, deliberately maximizing performance variance.Then, we optimize the policy to perform well on challenging groups. Lastly, leveraging the established groups, our approach adaptively adjusts the exploration space, allocating more learning capacity to more challenging data and preventing the model from over-optimizing on simpler data. Experimental results indicate that our approach significantly enhances training stability and model generalization.