Stack Attention: Improving the Ability of Transformers to Model Hierarchical Patterns
{kind=link}
Abstract
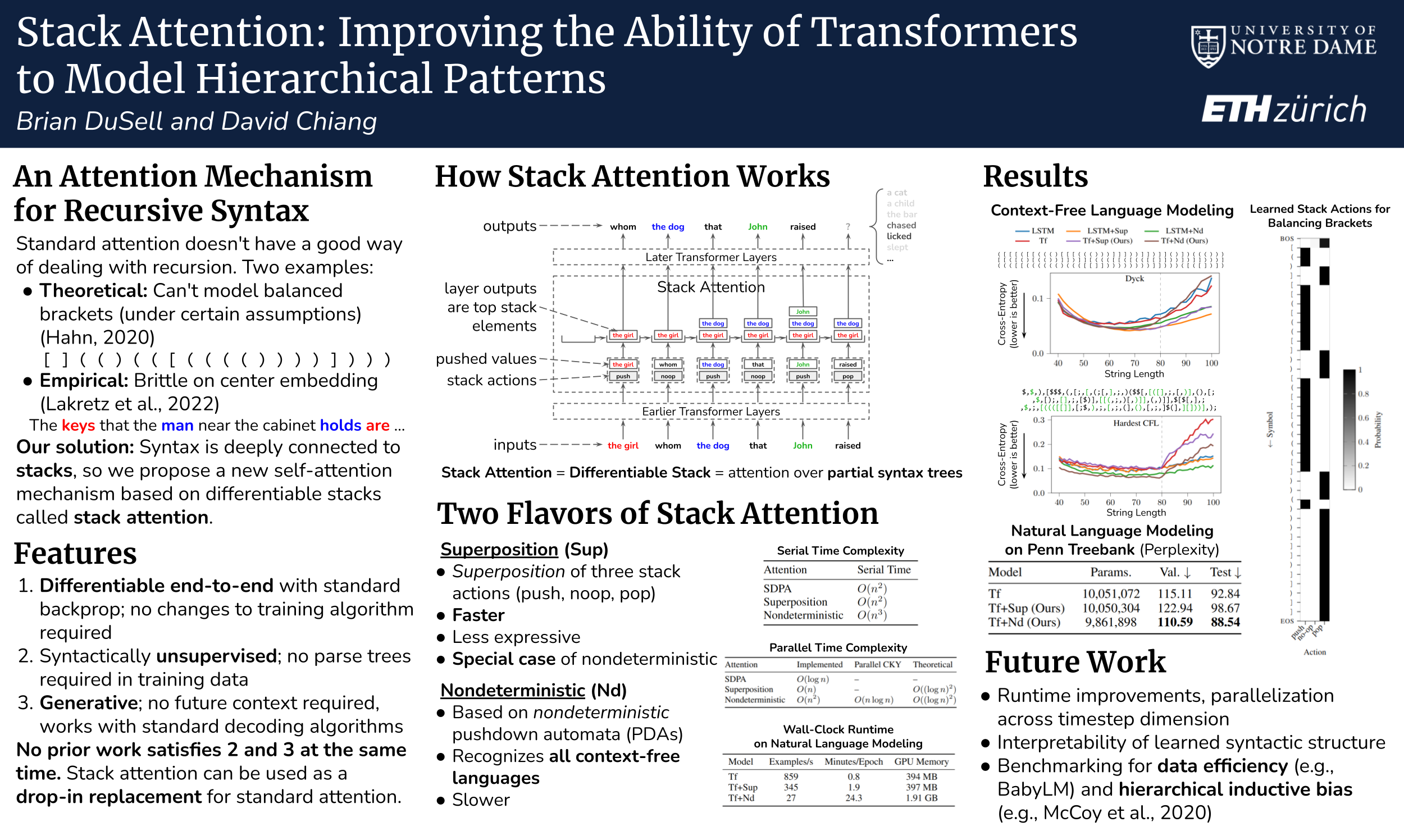
Attention, specifically scaled dot-product attention, has proven effective for natural language, but it does not have a mechanism for handling hierarchical patterns of arbitrary nesting depth, which limits its ability to recognize certain syntactic structures. To address this shortcoming, we propose stack attention: an attention operator that incorporates stacks, inspired by their theoretical connections to context-free languages (CFLs). We show that stack attention is analogous to standard attention, but with a latent model of syntax that requires no syntactic supervision. We propose two variants: one related to deterministic pushdown automata (PDAs) and one based on nondeterministic PDAs, which allows transformers to recognize arbitrary CFLs. We show that transformers with stack attention are very effective at learning CFLs that standard transformers struggle on, achieving strong results on a CFL with theoretically maximal parsing difficulty. We also show that stack attention is more effective at natural language modeling under a constrained parameter budget, and we include results on machine translation.