Less or More From Teacher: Exploiting Trilateral Geometry For Knowledge Distillation
Chengming Hu ⋅ Haolun Wu ⋅ Xuan Li ⋅ Chen Ma ⋅ Xi Chen ⋅ Boyu Wang ⋅ Jun Yan ⋅ Xue Liu
2024 Poster
{kind=link}
Abstract
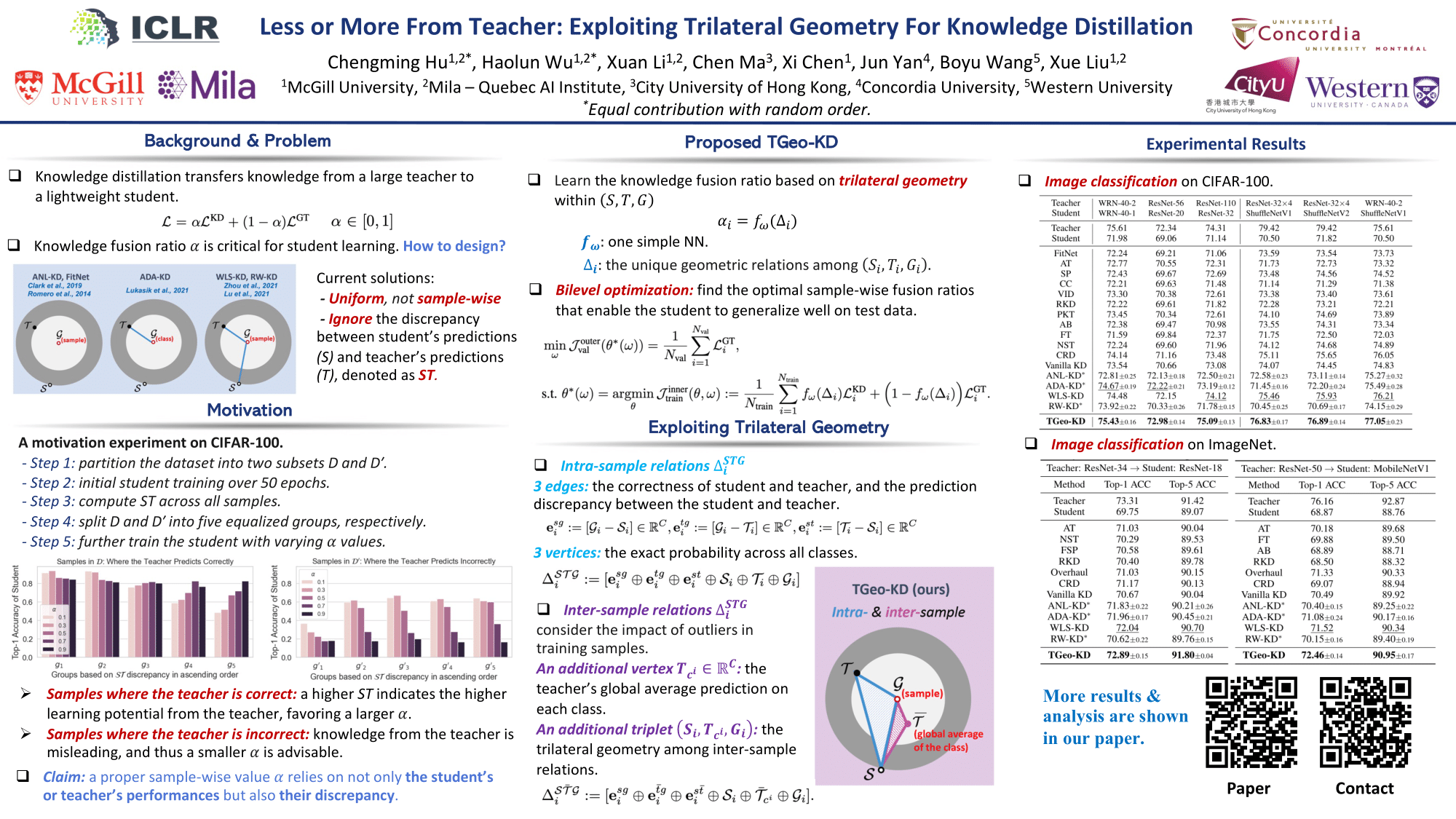
Knowledge distillation aims to train a compact student network using soft supervision from a larger teacher network and hard supervision from ground truths. However, determining an optimal knowledge fusion ratio that balances these supervisory signals remains challenging. Prior methods generally resort to a constant or heuristic-based fusion ratio, which often falls short of a proper balance. In this study, we introduce a novel adaptive method for learning a sample-wise knowledge fusion ratio, exploiting both the correctness of teacher and student, as well as how well the student mimics the teacher on each sample. Our method naturally leads to the \textit{intra-sample} trilateral geometric relations among the student prediction ($\mathcal{S}$), teacher prediction ($\mathcal{T}$), and ground truth ($\mathcal{G}$). To counterbalance the impact of outliers, we further extend to the \textit{inter-sample} relations, incorporating the teacher's global average prediction ($\mathcal{\bar{T}})$ for samples within the same class. A simple neural network then learns the implicit mapping from the intra- and inter-sample relations to an adaptive, sample-wise knowledge fusion ratio in a bilevel-optimization manner. Our approach provides a simple, practical, and adaptable solution for knowledge distillation that can be employed across various architectures and model sizes. Extensive experiments demonstrate consistent improvements over other loss re-weighting methods on image classification, attack detection, and click-through rate prediction.
Video
Chat is not available.
Successful Page Load