AMAGO: Scalable In-Context Reinforcement Learning for Adaptive Agents
{kind=link}
Abstract
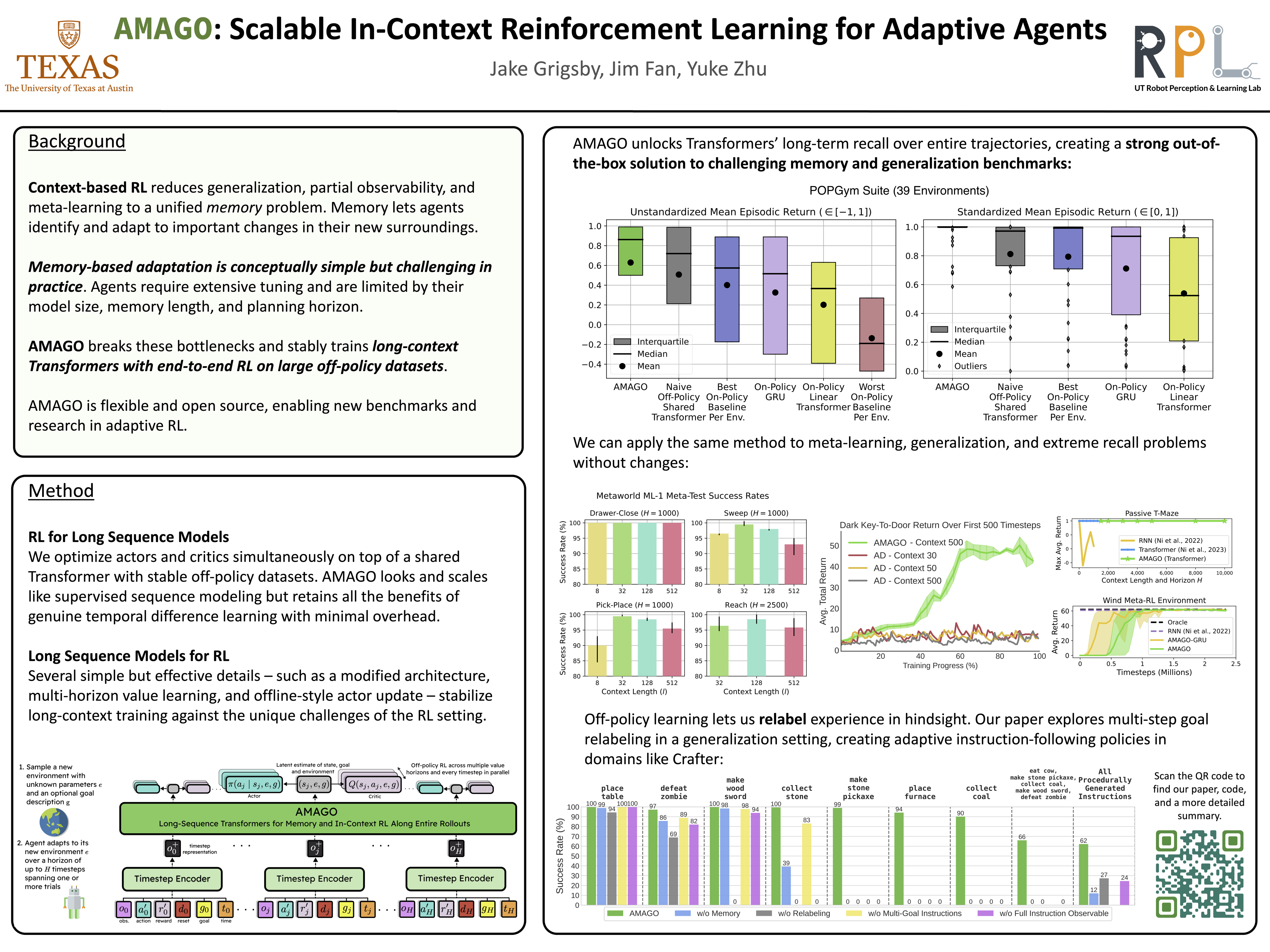
We introduce AMAGO, an in-context Reinforcement Learning (RL) agent that uses sequence models to tackle the challenges of generalization, long-term memory, and meta-learning. Recent works have shown that off-policy learning can make in-context RL with recurrent policies viable. Nonetheless, these approaches require extensive tuning and limit scalability by creating key bottlenecks in agents' memory capacity, planning horizon, and model size. AMAGO revisits and redesigns the off-policy in-context approach to successfully train long-sequence Transformers over entire rollouts in parallel with end-to-end RL. Our agent is scalable and applicable to a wide range of problems, and we demonstrate its strong performance empirically in meta-RL and long-term memory domains. AMAGO's focus on sparse rewards and off-policy data also allows in-context learning to extend to goal-conditioned problems with challenging exploration. When combined with a multi-goal hindsight relabeling scheme, AMAGO can solve a previously difficult category of open-world domains, where agents complete many possible instructions in procedurally generated environments.