SEA: Sparse Linear Attention with Estimated Attention Mask
{kind=link}
Abstract
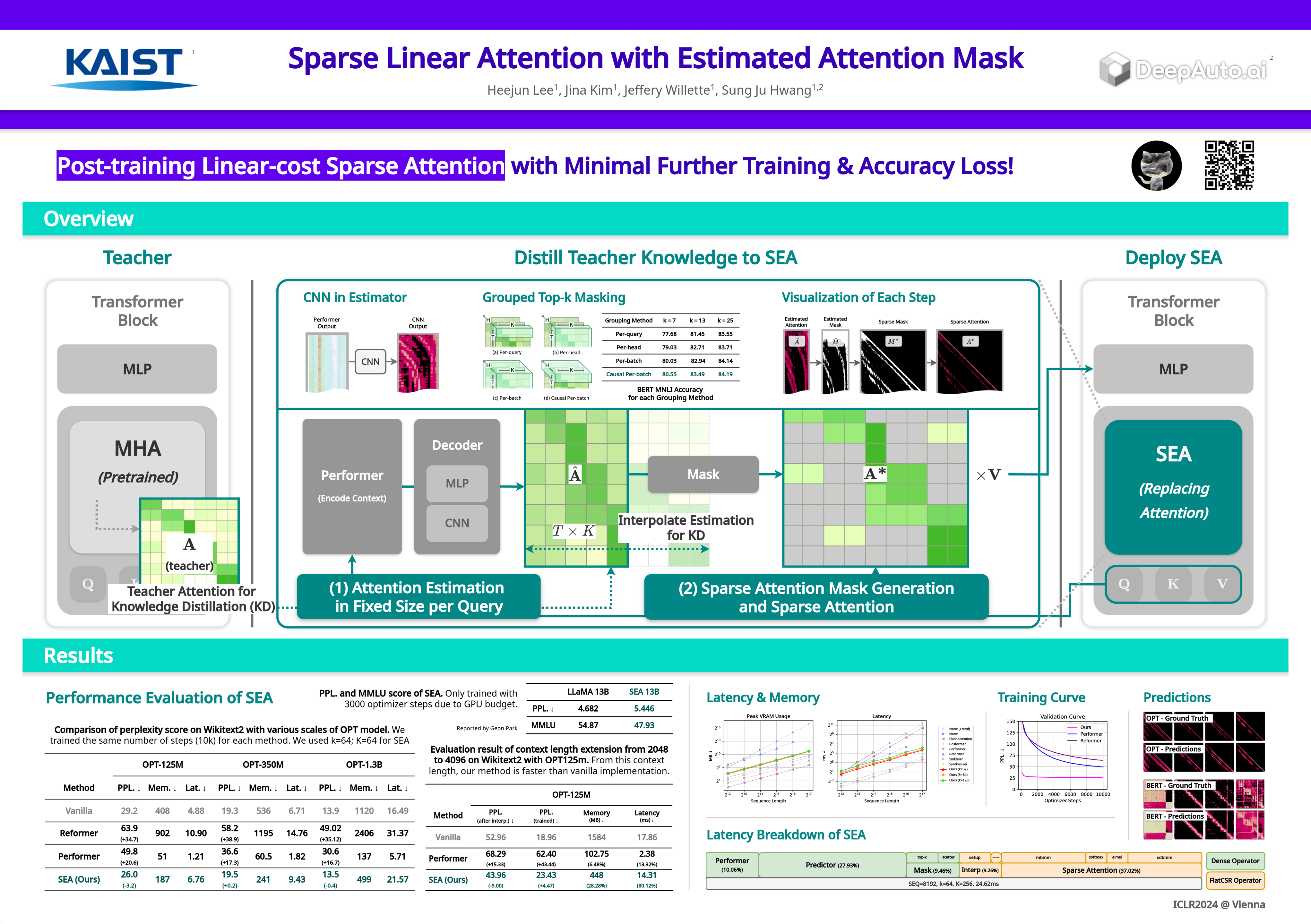
The transformer architecture has driven breakthroughs in recent years on taskswhich require modeling pairwise relationships between sequential elements, asis the case in natural language understanding. However, long seqeuences pose aproblem due to the quadratic complexity of the attention operation. Previous re-search has aimed to lower the complexity by sparsifying or linearly approximatingthe attention matrix. Yet, these approaches cannot straightforwardly distill knowl-edge from a teacher’s attention matrix, and often require complete retraining fromscratch. Furthermore, previous sparse and linear approaches lose interpretabilityif they cannot produce full attention matrices. To address these challenges, wepropose SEA: Sparse linear attention with an Estimated Attention mask. SEAestimates the attention matrix with linear complexity via kernel-based linear at-tention, then subsequently creates a sparse attention matrix with a top-k̂ selectionto perform a sparse attention operation. For language modeling tasks (Wikitext2),previous linear and sparse attention methods show roughly two-fold worse per-plexity scores over the quadratic OPT-1.3B baseline, while SEA achieves betterperplexity than OPT-1.3B, using roughly half the memory of OPT-1.3B. More-over, SEA maintains an interpretable attention matrix and can utilize knowledgedistillation to lower the complexity of existing pretrained transformers. We be-lieve that our work will have a large practical impact, as it opens the possibility ofrunning large transformers on resource-limited devices with less memory.Code: https://github.com/gmlwns2000/sea-attention