A Good Learner can Teach Better: Teacher-Student Collaborative Knowledge Distillation
Ayan Sengupta ⋅ Shantanu Dixit ⋅ Md Shad Akhtar ⋅ Tanmoy Chakraborty
2024 Poster
{kind=link}
Abstract
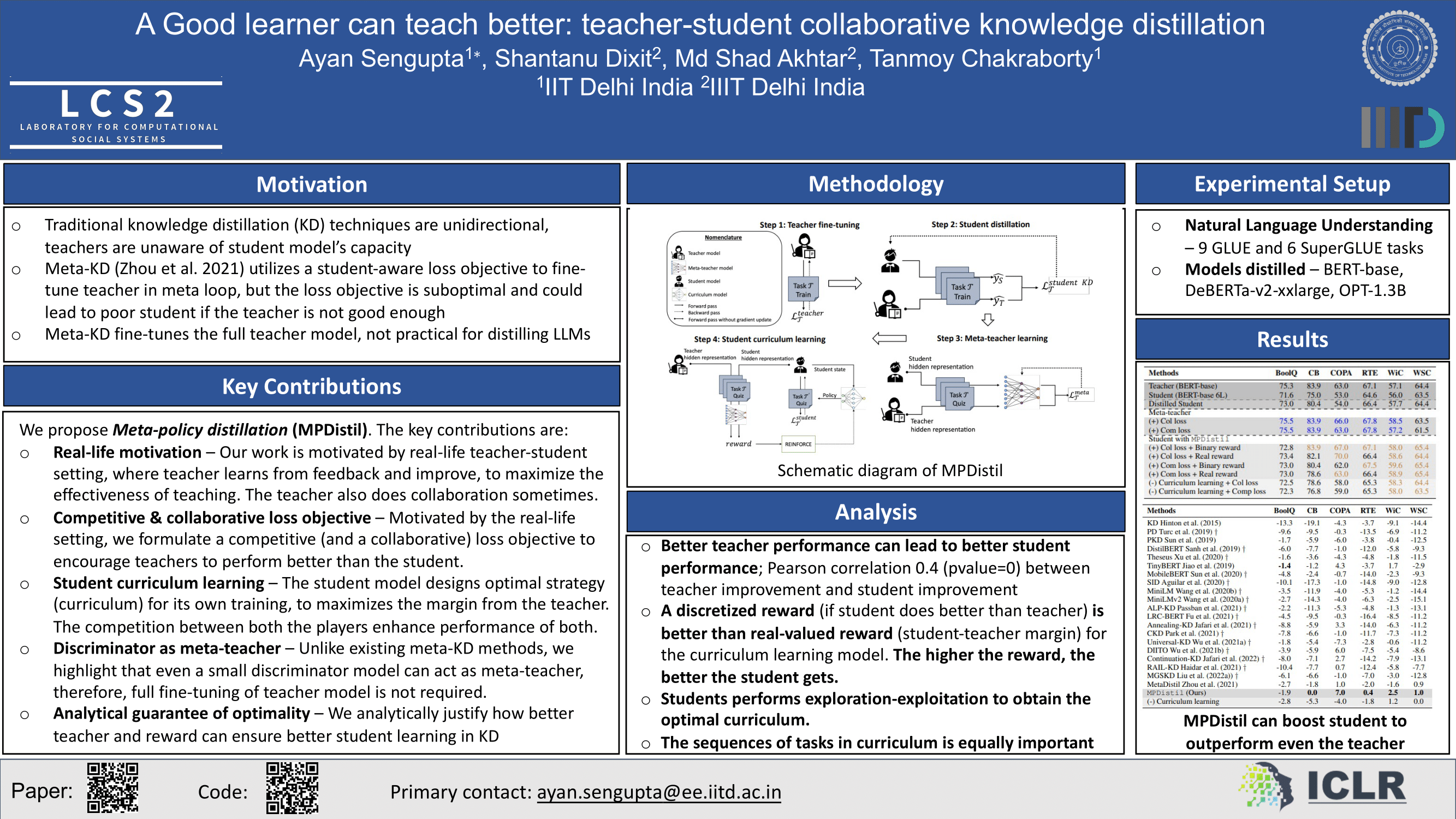
Knowledge distillation (KD) is a technique used to transfer knowledge from a larger ''teacher'' model into a smaller ''student'' model. Recent advancements in meta-learning-based knowledge distillation (MetaKD) emphasize that the fine-tuning of teacher models should be aware of the student's need to achieve better knowledge distillation. However, existing MetaKD methods often lack incentives for the teacher model to improve itself. In this study, we introduce MPDistil, a meta-policy distillation technique, that utilizes novel optimization strategies to foster both *collaboration* and *competition* during the fine-tuning of the teacher model in the meta-learning step. Additionally, we propose a curriculum learning framework for the student model in a competitive setup, in which the student model aims to outperform the teacher model by self-training on various tasks. Exhaustive experiments on SuperGLUE and GLUE benchmarks demonstrate the efficacy of MPDistil compared to $20$ conventional KD and advanced MetaKD baselines, showing significant performance enhancements in the student model -- e.g., a distilled 6-layer BERT model outperforms a 12-layer BERT model on five out of six SuperGLUE tasks. Furthermore, MPDistil, while applied to a large language teacher model (DeBERTa-v2-xxlarge), significantly narrows the performance gap of its smaller student counterpart (DeBERTa-12) by just $4.6$% on SuperGLUE. We further demonstrate how higher rewards and customized training curricula strengthen the student model and enhance generalizability.
Video
Chat is not available.
Successful Page Load