LLM-CXR: Instruction-Finetuned LLM for CXR Image Understanding and Generation
{kind=link}
Abstract
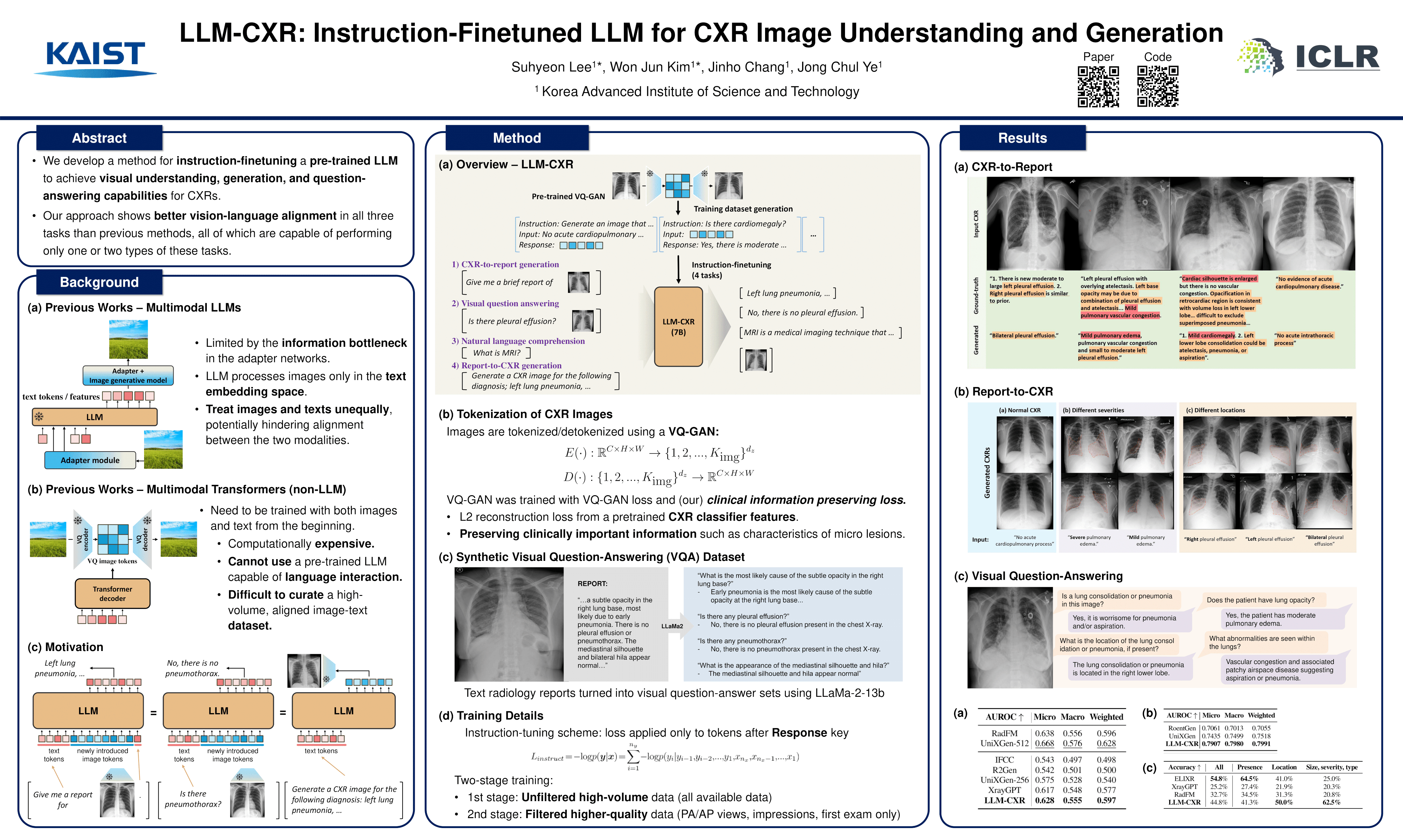
Following the impressive development of LLMs, vision-language alignment in LLMs is actively being researched to enable multimodal reasoning and visual input/output. This direction of research is particularly relevant to medical imaging because accurate medical image analysis and generation consist of a combination of reasoning based on visual features and prior knowledge. Many recent works have focused on training adapter networks that serve as an information bridge between image processing (encoding or generating) networks and LLMs; but presumably, in order to achieve maximum reasoning potential of LLMs on visual information as well, visual and language features should be allowed to interact more freely. This is especially important in the medical domain because understanding and generating medical images such as chest X-rays (CXR) require not only accurate visual and language-based reasoning but also a more intimate mapping between the two modalities. Thus, taking inspiration from previous work on the transformer and VQ-GAN combination for bidirectional image and text generation, we build upon this approach and develop a method for instruction-tuning an LLM pre-trained only on text to gain vision-language capabilities for medical images. Specifically, we leverage a pretrained LLM’s existing question-answering and instruction-following abilities to teach it to understand visual inputs by instructing it to answer questions about image inputs and, symmetrically, output both text and image responses appropriate to a given query by tuning the LLM with diverse tasks that encompass image-based text-generation and text-based image-generation. We show that our LLM-CXR trained in this approach shows better image-text alignment in both CXR understanding and generation tasks while being smaller in size compared to previously developed models that perform a narrower range of tasks.