Fast-ELECTRA for Efficient Pre-training
{kind=link}
Abstract
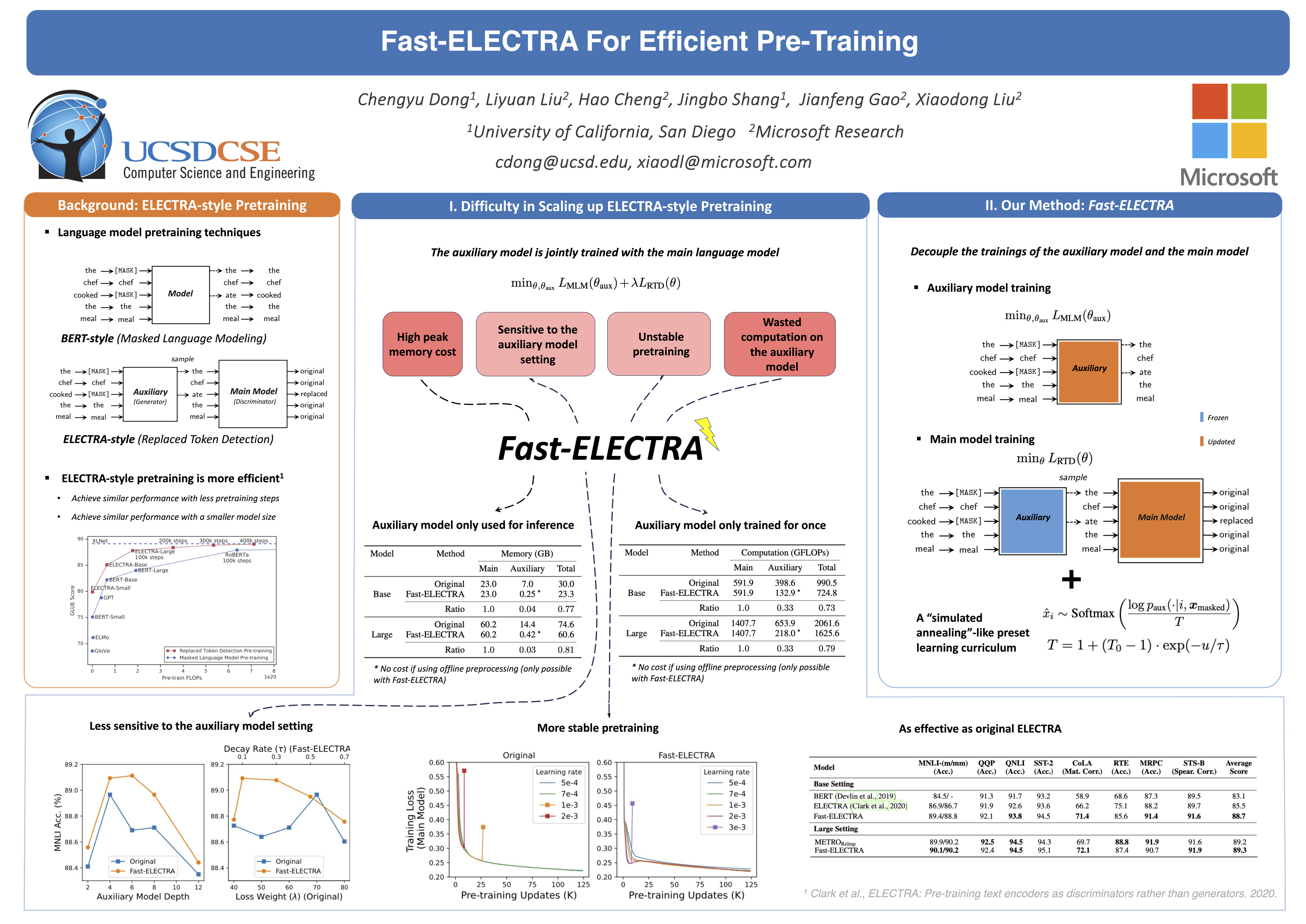
ELECTRA pre-trains language models by detecting tokens in a sequence that have been replaced by an auxiliary model. Although ELECTRA offers a significant boost in efficiency, its potential is constrained by the training cost brought by the auxiliary model. Notably, this model, which is jointly trained with the main model, only serves to assist the training of the main model and is discarded post-training. This results in a substantial amount of training cost being expended in vain. To mitigate this issue, we propose Fast-ELECTRA, which leverages an existing language model as the auxiliary model. To construct a learning curriculum for the main model, we smooth its output distribution via temperature scaling following a descending schedule. Our approach rivals the performance of state-of-the-art ELECTRA-style pre-training methods, while significantly eliminating the computation and memory cost brought by the joint training of the auxiliary model. Our method also reduces the sensitivity to hyper-parameters and enhances the pre-training stability.