BTR: Binary Token Representations for Efficient Retrieval Augmented Language Models
{kind=link}
Abstract
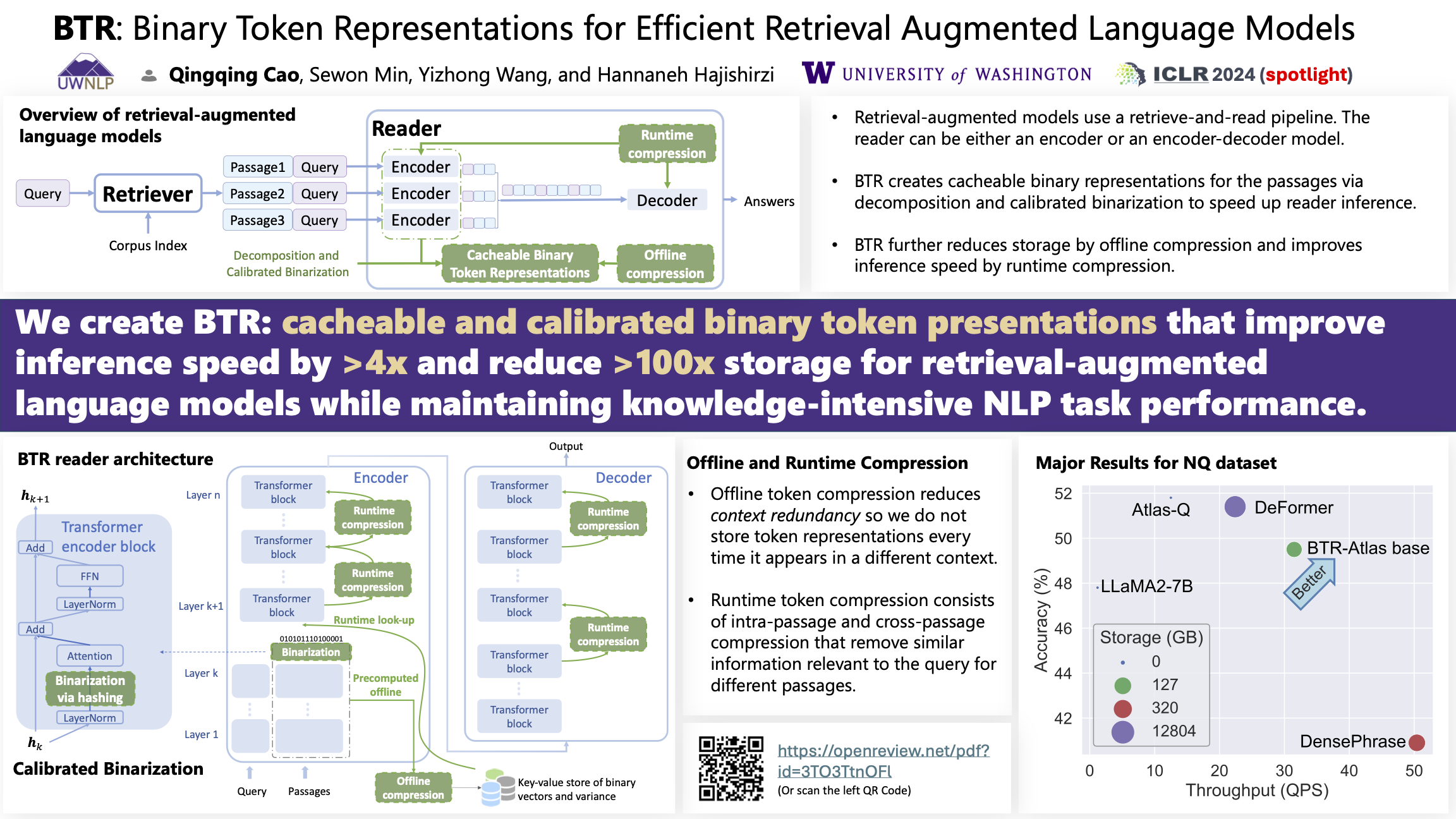
Retrieval augmentation addresses many critical problems in large language models such as hallucination, staleness, and privacy leaks.However, running retrieval-augmented language models (LMs) is slow and difficult to scale due to processing large amounts of retrieved text. We introduce binary token representations (BTR), which use 1-bit vectors to precompute every token in passages, significantly reducing computation during inference. Despite the potential loss of accuracy, our new calibration techniques and training objectives restore performance. Combined with offline and runtime compression, this only requires 127GB of disk space for encoding 3 billion tokens in Wikipedia.Our experiments show that on five knowledge-intensive NLP tasks, BTR accelerates state-of-the-art inference by up to 4x and reduces storage by over 100x while maintaining over 95% task performance. Our code is publicly available at https://github.com/csarron/BTR.