On Representation Complexity of Model-based and Model-free Reinforcement Learning
Hanlin Zhu ⋅ Baihe Huang ⋅ Stuart Russell
2024 Poster
{kind=link}
Abstract
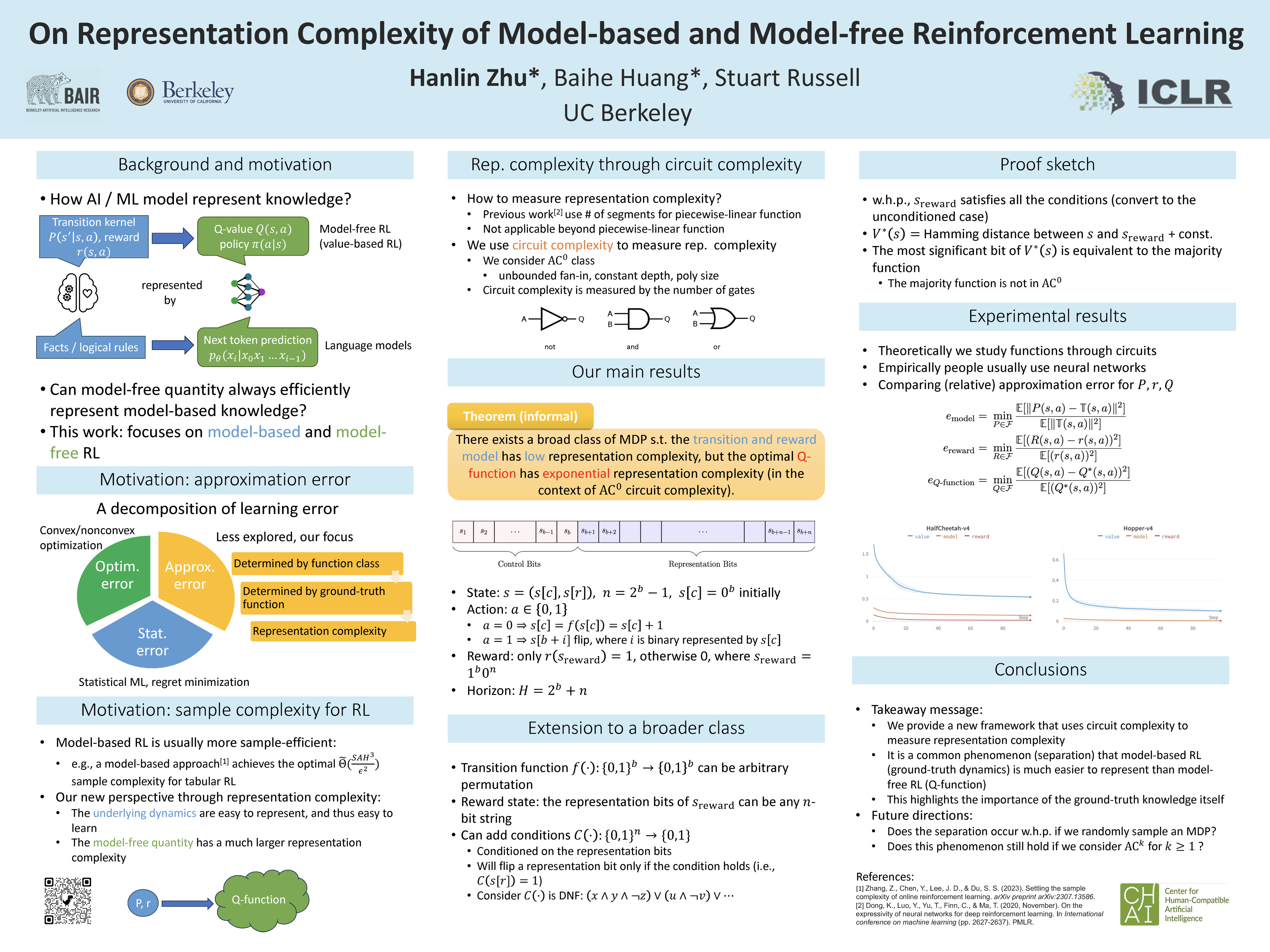
We study the representation complexity of model-based and model-free reinforcement learning (RL) in the context of circuit complexity. We prove theoretically that there exists a broad class of MDPs such that their underlying transition and reward functions can be represented by constant depth circuits with polynomial size, while the optimal $Q$-function suffers an exponential circuit complexity in constant-depth circuits. By drawing attention to the approximation errors and building connections to complexity theory, our theory provides unique insights into why model-based algorithms usually enjoy better sample complexity than model-free algorithms from a novel representation complexity perspective: in some cases, the ground-truth rule (model) of the environment is simple to represent, while other quantities, such as $Q$-function, appear complex. We empirically corroborate our theory by comparing the approximation error of the transition kernel, reward function, and optimal $Q$-function in various Mujoco environments, which demonstrates that the approximation errors of the transition kernel and reward function are consistently lower than those of the optimal $Q$-function. To the best of our knowledge, this work is the first to study the circuit complexity of RL, which also provides a rigorous framework for future research.
Video
Chat is not available.
Successful Page Load