Polynomial Width is Sufficient for Set Representation with High-dimensional Features
Peihao Wang ⋅ Shenghao Yang ⋅ Shu Li ⋅ Zhangyang Wang ⋅ Pan Li
2024 Poster
{kind=link}
Abstract
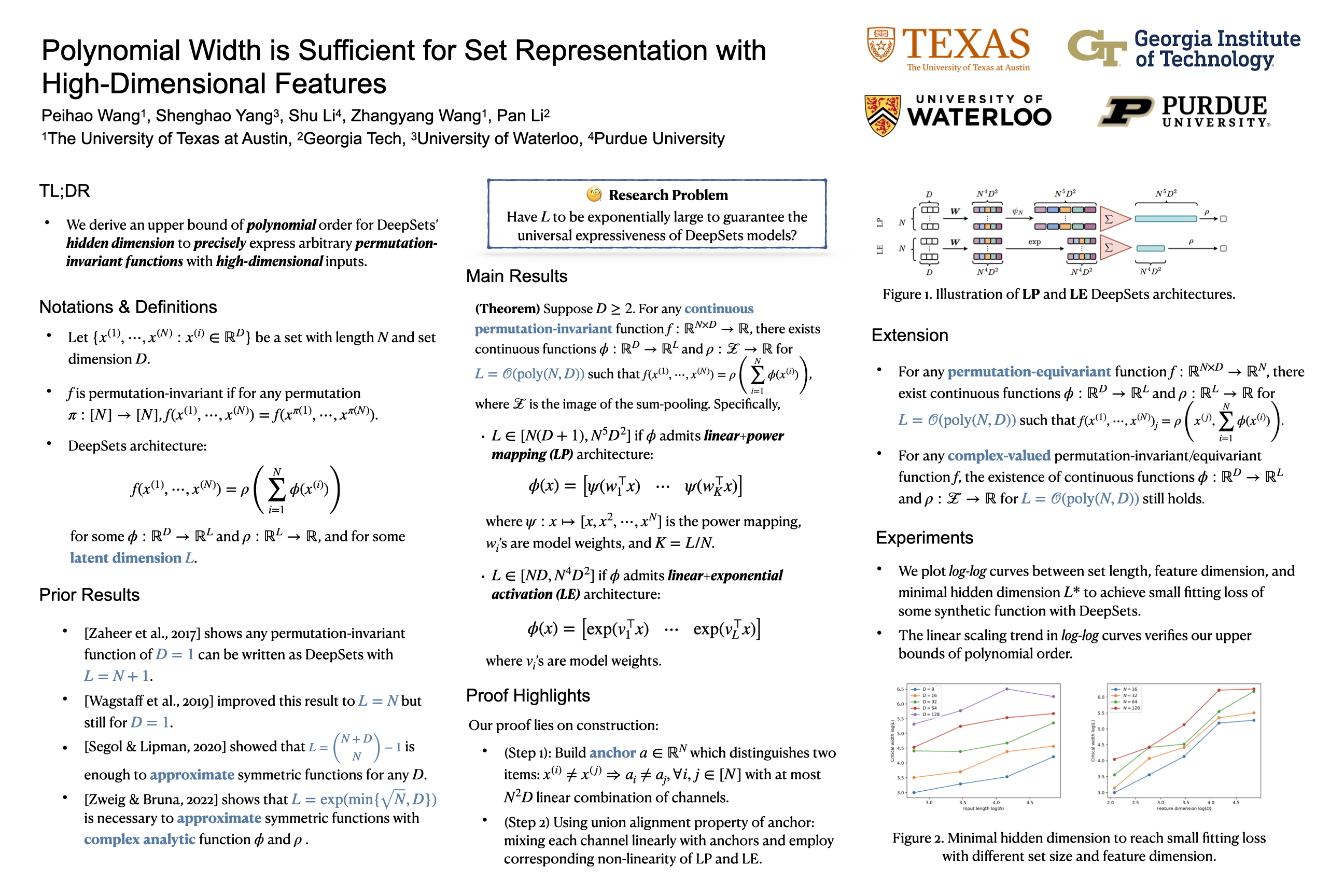
Set representation has become ubiquitous in deep learning for modeling the inductive bias of neural networks that are insensitive to the input order. DeepSets is the most widely used neural network architecture for set representation. It involves embedding each set element into a latent space with dimension $L$, followed by a sum pooling to obtain a whole-set embedding, and finally mapping the whole-set embedding to the output. In this work, we investigate the impact of the dimension $L$ on the expressive power of DeepSets. Previous analyses either oversimplified high-dimensional features to be one-dimensional features or were limited to complex analytic activations, thereby diverging from practical use or resulting in $L$ that grows exponentially with the set size $N$ and feature dimension $D$. To investigate the minimal value of $L$ that achieves sufficient expressive power, we present two set-element embedding layers: (a) linear + power activation (LP) and (b) linear + exponential activations (LE). We demonstrate that $L$ being $\operatorname{poly}(N, D)$ is sufficient for set representation using both embedding layers. We also provide a lower bound of $L$ for the LP embedding layer. Furthermore, we extend our results to permutation-equivariant set functions and the complex field.
Video
Chat is not available.
Successful Page Load