OmniNav: A Unified Framework for Prospective Exploration and Visual-Language Navigation
{kind=link}
Abstract
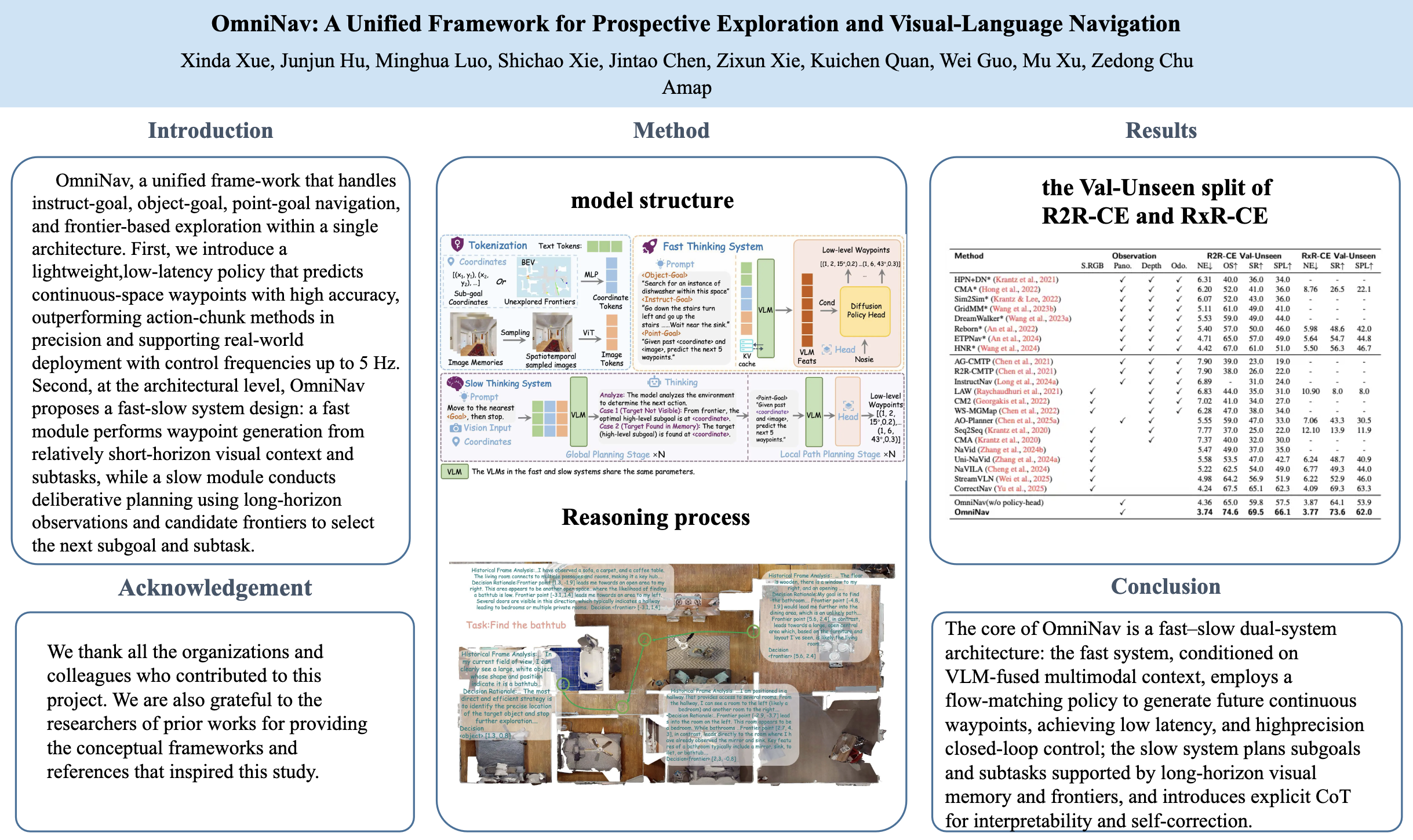
Embodied navigation is a foundational challenge for intelligent robots, demanding the ability to comprehend visual environments, follow natural language instructions, and explore autonomously. However, existing models struggle to provide a unified solution across heterogeneous navigation paradigms, often yielding low success rates and limited generalization. We present OmniNav, a unified framework that handles instruct-goal, object-goal, point-goal navigation, and frontier-based exploration within a single architecture. First, we introduce a lightweight, low-latency policy that predicts continuous-space waypoints (coordinates and orientations) with high accuracy, outperforming action-chunk methods in precision and supporting real-world deployment with control frequencies up to 5 Hz. Second, at the architectural level, OmniNav proposes a fast-slow system design: a fast module performs waypoint generation from relatively short-horizon visual context and subtasks, while a slow module conducts deliberative planning using long-horizon observations and candidate frontiers to select the next subgoal and subtask. This collaboration improves path efficiency and maintains trajectory coherence in exploration and memory-intensive settings. Notably, we find that the primary bottleneck lies not in navigation policy learning per se, but in robust understanding of general instructions and objects. To enhance generalization, we incorporate large-scale general-purpose training datasets including those used for image captioning and referring/grounding into a joint multi-task regimen, which substantially boosts success rates and robustness. Extensive experiments demonstrate state-of-the-art performance across diverse navigation benchmarks, and real-world deployment further validates the approach. OmniNav offers practical insights for embodied navigation and points to a scalable path toward versatile, highly generalizable robotic intelligence.