How to train data-efficient LLMs
Noveen Sachdeva ⋅ Benjamin Coleman ⋅ Wang-Cheng Kang ⋅ Jianmo Ni ⋅ Lichan Hong ⋅ Ed H. Chi ⋅ James Caverlee ⋅ Julian McAuley ⋅ Derek Cheng
{kind=link}
Abstract
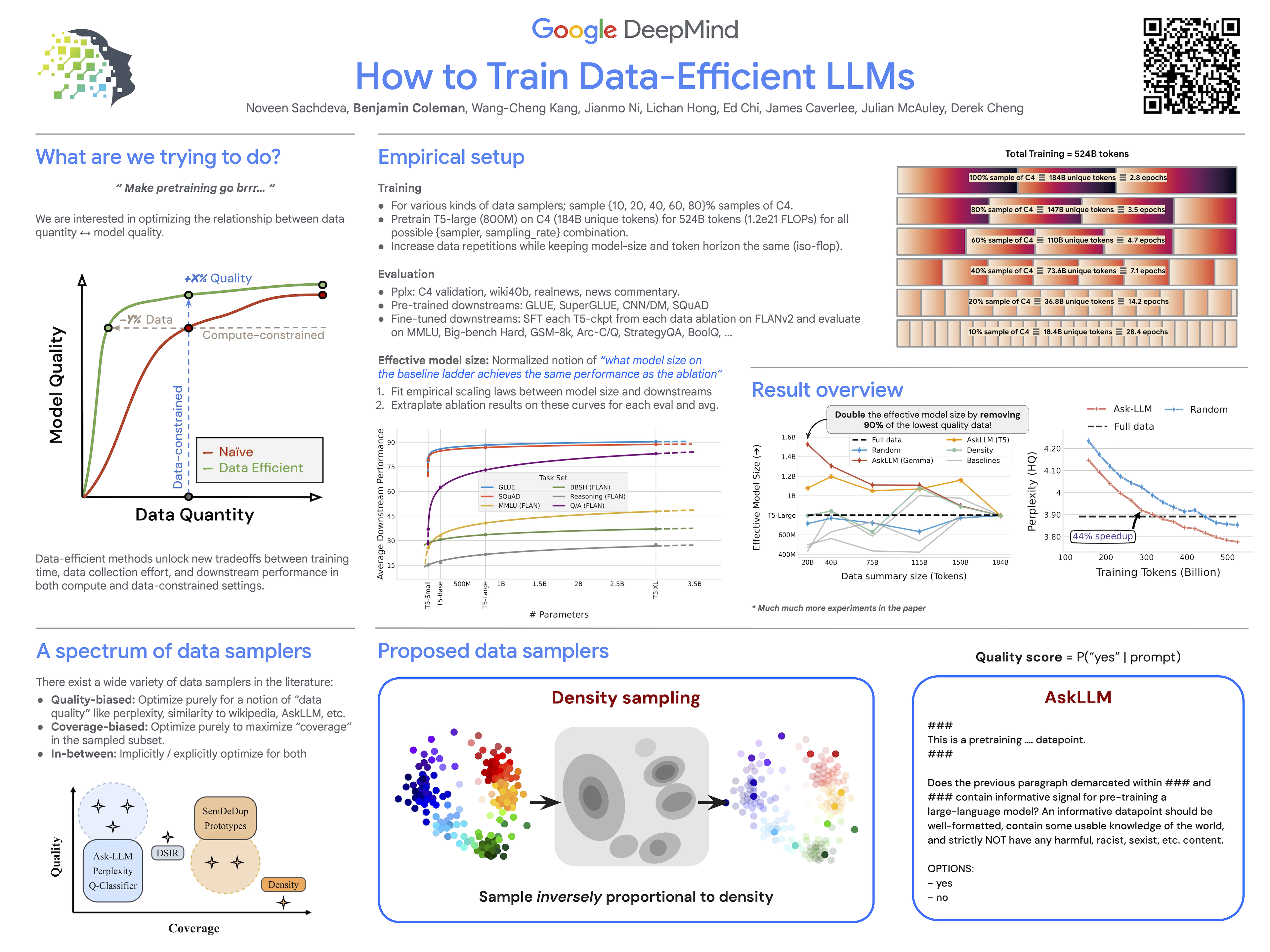
The training of large language models (LLMs) is expensive. In this paper, we study data-efficient approaches for pre-training LLMs, \ie, techniques that aim to optimize the Pareto frontier of model quality and training resource/data consumption. We seek to understand the tradeoffs associated with data selection routines based on (i) expensive-to-compute data-quality estimates, and (ii) maximization of coverage and diversity-based measures in the feature space. Our first technique, AskLLM, leverages the zero-shot reasoning capabilities of instruction-tuned LLMs to directly assess the quality of a training example. To target coverage, we propose density sampling, which models the data distribution to select a diverse sample. Testing the effect of $22$ different data curation techniques on the pre-training of T5-style of models, involving hundreds of pre-training runs and post fine-tuning evaluation tasks, we find that AskLLM and density are the best methods in their respective categories. While coverage sampling techniques often recover the performance of training on the entire dataset, training on data curated via AskLLM consistently outperforms full-data training---even when we sample only $10$\% of the original dataset, while converging up to $70$\% faster.
Video
Chat is not available.
Successful Page Load