PERK: Long-Context Reasoning as Parameter-Efficient Test-Time Learning
{kind=link}
Abstract
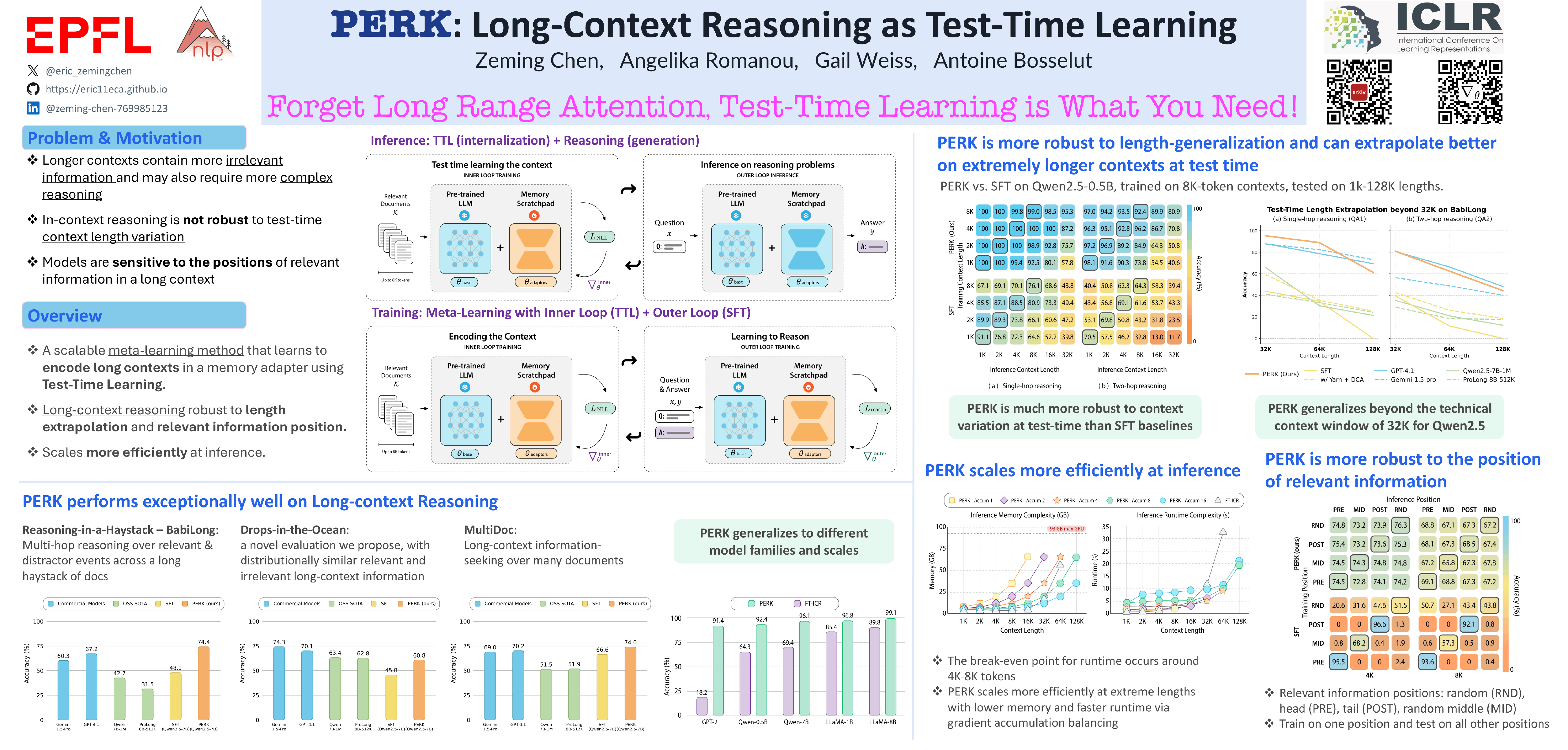
Long-context reasoning requires accurately identifying relevant information in extensive, noisy input contexts. In this work, we propose PERK (Parameter Efficient Reasoning over Knowledge), a scalable approach for learning to encode long contexts using gradient updates at test time. Specifically, PERK employs two nested optimization loops in a meta-training phase. The inner loop rapidly encodes contexts into a low-rank adapter (LoRA) that serves as a parameter-efficient memory module for the base model. Concurrently, the outer loop learns to use the updated adapter to accurately recall and reason over relevant information from the encoded long context. Our evaluations on several long-context reasoning tasks show that PERK significantly outperforms the standard long-context finetuning, achieving average absolute performance gains of up to 20% for Qwen-2.5 (0.5B & 7B) on synthetic and real-world long-context reasoning. PERK also maintains its advantages across model scales and families. Compared to specialized long-context LLMs, PERK matches or surpasses their performance. Finally, our analyses show PERK is more robust to reasoning complexity, length extrapolation, and the positions of relevant information in contexts.