Adaptive Width Neural Networks
{kind=link}
Abstract
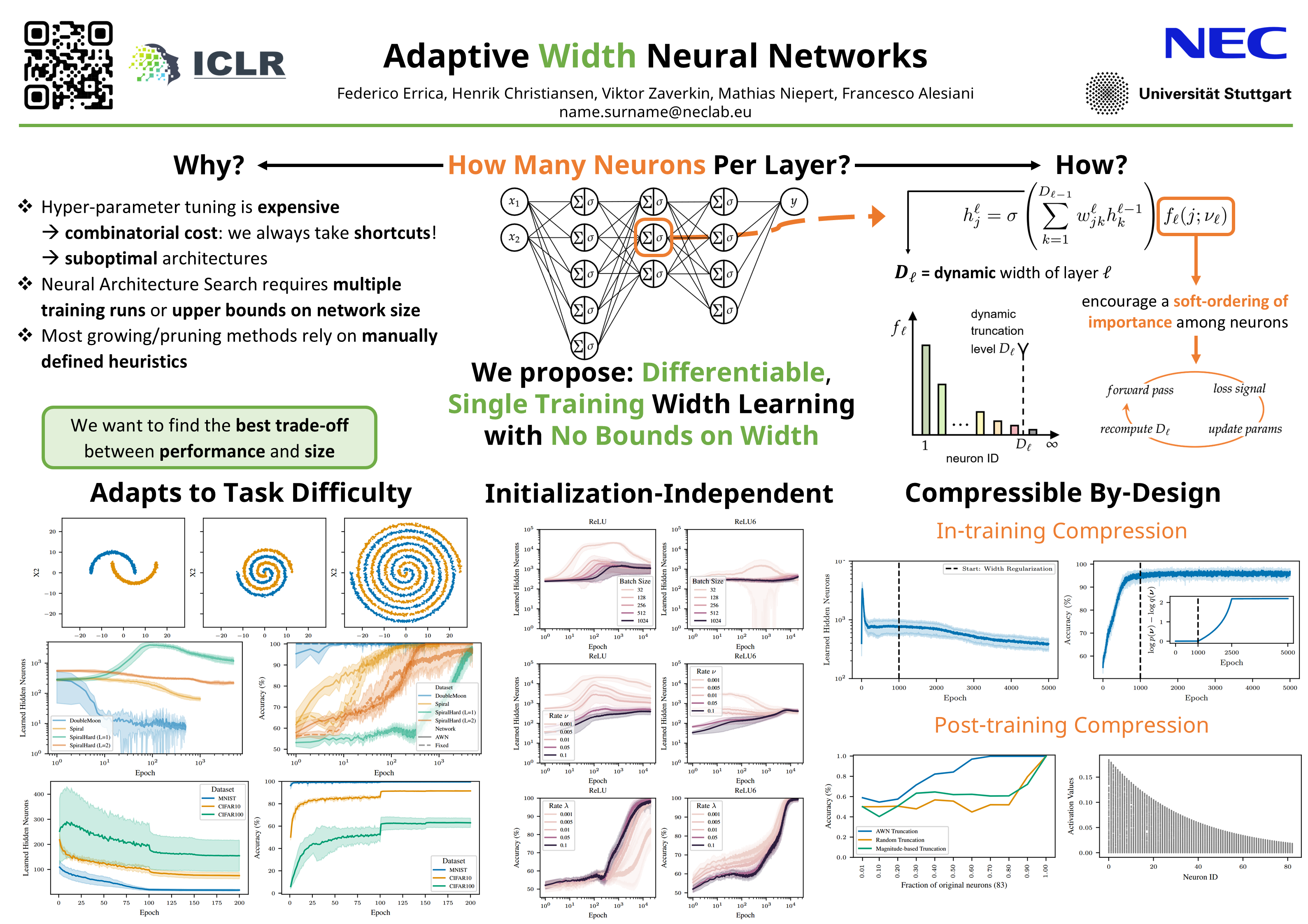
For almost 70 years, researchers have typically selected the width of neural networks’ layers either manually or through automated hyperparameter tuning methods such as grid search and, more recently, neural architecture search. This paper challenges the status quo by introducing an easy-to-use technique to learn an \textit{unbounded} width of a neural network's layer \textit{during training}. The method jointly optimizes the width and the parameters of each layer via standard backpropagation. We apply the technique to a broad range of data domains such as tables, images, text, sequences, and graphs, showing how the width adapts to the task's difficulty. A by product of our width learning approach is the easy truncation of the trained network at virtually zero cost, achieving a smooth trade-off between performance and compute resources. Alternatively, one can dynamically compress the network until performances do not degrade. In light of recent foundation models trained on large datasets, requiring billions of parameters and where hyper-parameter tuning is unfeasible due to huge training costs, our approach introduces a viable alternative for width learning.