CrossPL: Systematic Evaluation of Large Language Models for Cross Programming Language Interoperating Code Generation
{kind=link}
Abstract
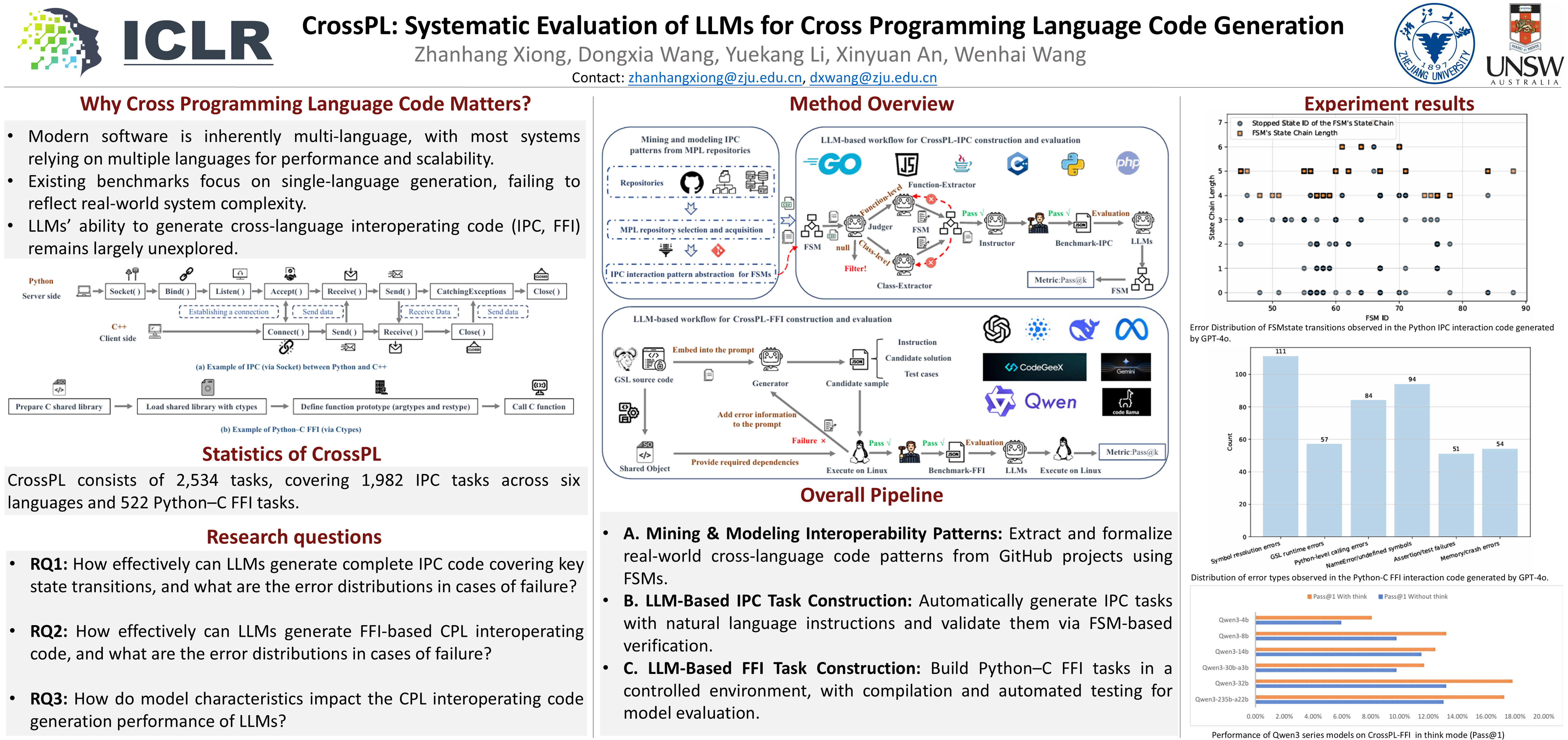
Large language models (LLMs) have shown strong performance in single-language code generation, but how well they produce cross-programming-language (CPL) interoperating code, which is widely used in cross-platform and complex software systems, remains underexplored. Therefore, a benchmark for evaluating CPL interaction code generation is essential. However, Constructing such a benchmark is challenging owing to sparse interoperating code in real-world multi-programming-language projects, diverse Inter-process Communication (IPC) mechanisms, vast Foreign Function Interface (FFI) language pairs, and the difficulty of evaluation. To address this gap, we introduce CrossPL, the first benchmark for systematically assessing LLM performance of CPL code generation across two primary interoperation modes and 2534 tasks, specifically 1,982 IPC tasks spanning six languages and 522 Python–C FFI tasks. Its construction involved a review of CPL documentation, 156 finite state machines, and analysis of 19,169 multi-language GitHub repositories. Two LLM-based workflows are designed for automating the benchmark construction and evaluation, and assess 20 state-of-the-art LLMs. Results reveal clear limitations: the best model achieves only 19.5\% Pass@1 and 26.46\% Pass@5 on the FFI subset, in sharp contrast to the strong performance of these models on single-language benchmarks. These findings underscore the urgent need for improving LLMs regarding CPL interoperating code generation. The benchmark and code are available at https://github.com/newxzh/crosspl.