Object-Centric Refinement for Enhanced Zero-Shot Segmentation
{kind=link}
Abstract
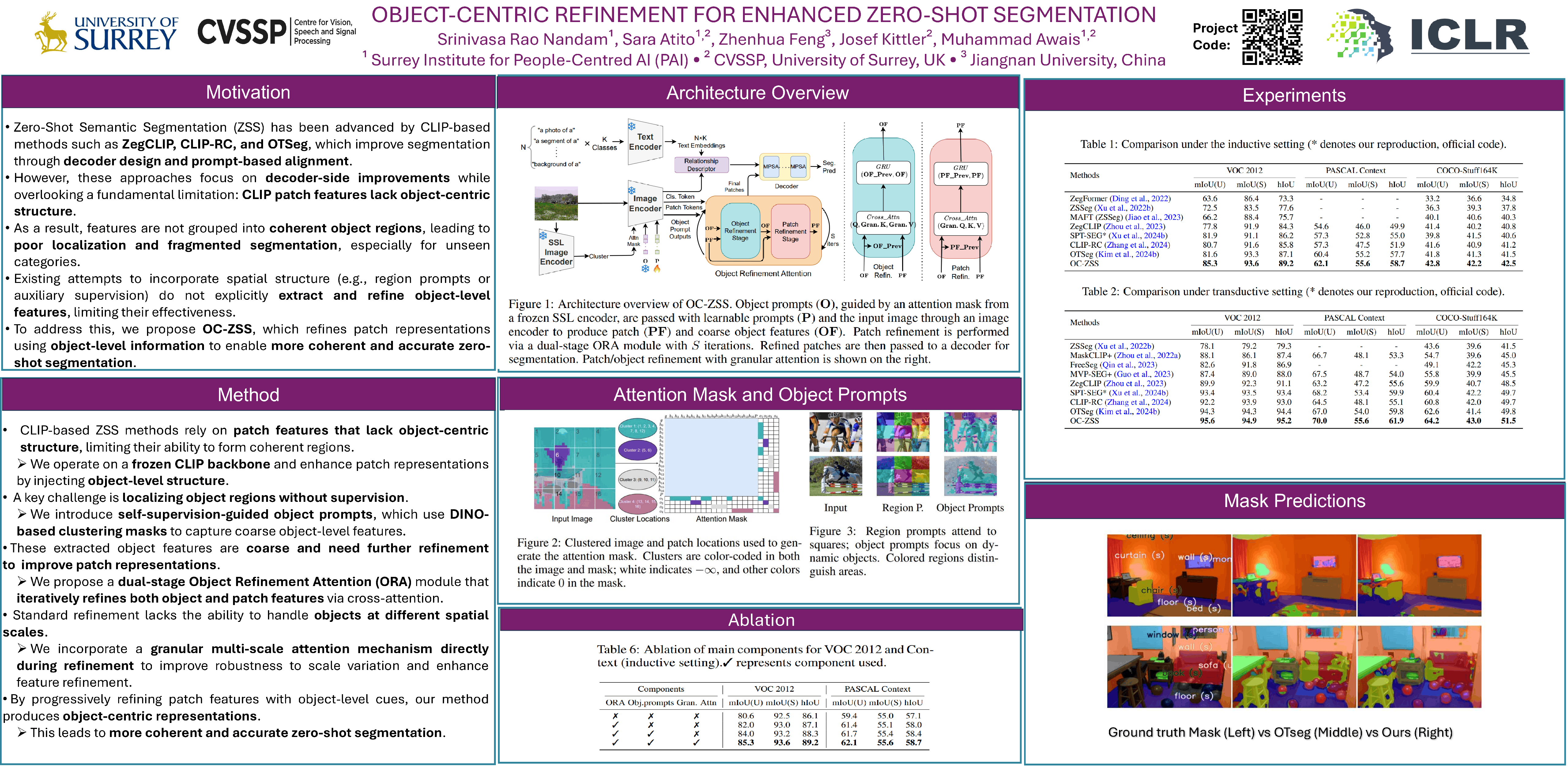
Zero-shot semantic segmentation aims to recognize, pixel-wise, unseen categories without annotated masks, typically by leveraging vision-language models such as CLIP. However, the patch representations obtained by the CLIP's vision encoder lack object-centric structure, making it difficult to localize coherent semantic regions. This hinders the performance of the segmentation decoder, especially for unseen categories. To mitigate this issue, we propose object-centric zero-shot segmentation (OC-ZSS) that enhances patch representations using object-level information. To extract object features for patch refinement, we introduce self-supervision-guided object prompts into the encoder. These prompts attend to coarse object regions using attention masks derived from unsupervised clustering of features from a pretrained self-supervised~(SSL) model. Although these prompts offer a structured initialization of the object-level context, the extracted features remain coarse due to the unsupervised nature of clustering. To further refine the object features and effectively enrich patch representations, we develop a dual-stage Object Refinement Attention (ORA) module that iteratively updates both object and patch features through cross-attention. Last, to make the refinement more robust and sensitive to objects of varying spatial scales, we incorporate a lightweight granular attention mechanism that operates over multiple receptive fields. OC-ZSS achieves state-of-the-art performance on standard zero-shot segmentation benchmarks across inductive, transductive, and cross-domain settings.