MIRA: Memory-Integrated Reinforcement Learning Agent with Limited LLM Guidance
{kind=link}
Abstract
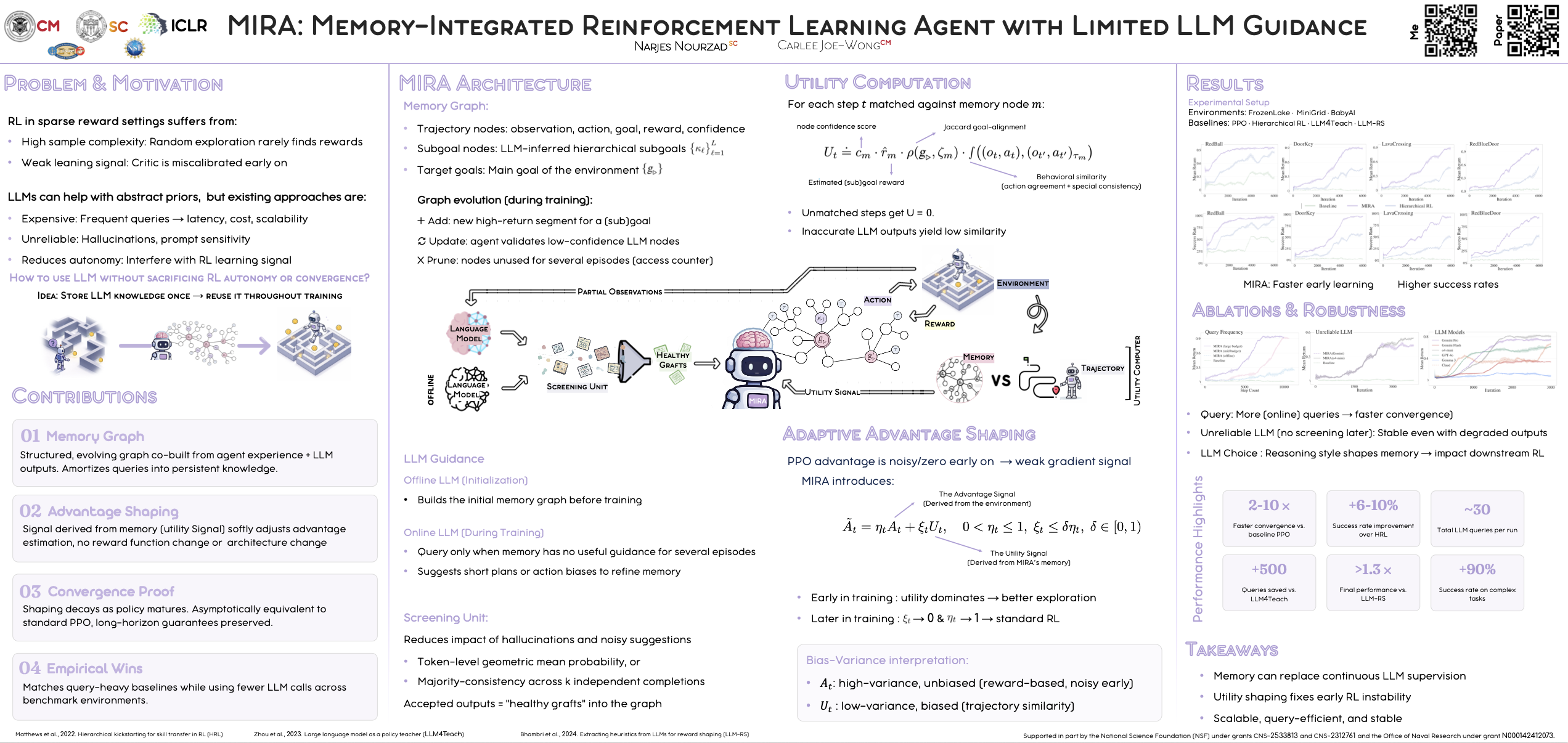
Reinforcement learning (RL) agents often face high sample complexity in sparse or delayed reward settings, due to limited prior knowledge. Conversely, large language models (LLMs) can provide subgoal structures, plausible trajectories, and abstract priors that support early learning. Yet heavy reliance on LLMs introduces scalability issues and risks dependence on unreliable signals, motivating ongoing efforts to integrate LLM guidance without compromising RL’s autonomy. We propose MIRA (Memory-Integrated Reinforcement Learning Agent), which incorporates a structured, evolving memory graph to guide early learning. This graph stores decision-relevant information, such as trajectory segments and subgoal decompositions, and is co-constructed from the agent’s high-return experiences and LLM outputs, amortizing LLM queries into a persistent memory instead of relying on continuous real-time supervision. From this structure, we derive a utility signal that softly adjusts advantage estimation to refine policy updates without altering the underlying reward function. As training progresses, the agent’s policy surpasses the initial LLM-derived priors, and the utility term decays, leaving long-term convergence guarantees intact. We show theoretically that this utility-based shaping improves early-stage learning in sparse-reward settings. Empirically, MIRA outperforms RL baselines and reaches returns comparable to methods that rely on frequent LLM supervision, while requiring substantially fewer online LLM queries.