EgoHandICL: Egocentric 3D Hand Reconstruction with In-Context Learning
{kind=link}
Abstract
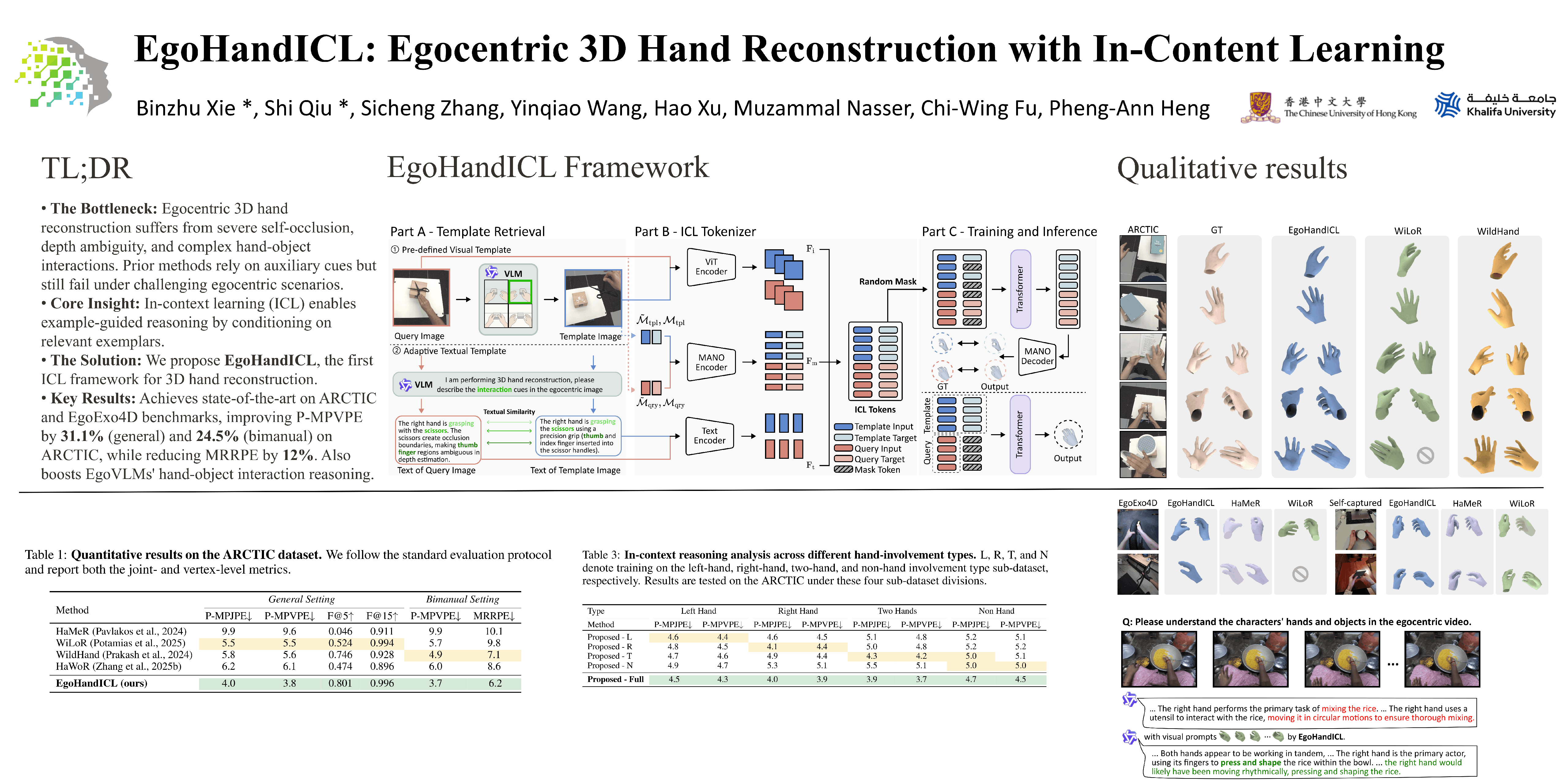
Robust 3D hand reconstruction is challenging in egocentric vision due to depth ambiguity, self-occlusion, and complex hand-object interactions. Prior works attempt to mitigate the challenges by scaling up training data or incorporating auxiliary cues, often falling short of effectively handling unseen contexts. In this paper, we introduce EgoHandICL, the first in-context learning (ICL) framework for 3D hand reconstruction that achieves strong semantic alignment, visual consistency, and robustness under challenging egocentric conditions. Specifically, we develop (i) complementary exemplar retrieval strategies guided by vision–language models (VLMs), (ii) an ICL-tailored tokenizer that integrates multimodal context, and (iii) a Masked Autoencoders (MAE)-based architecture trained with 3D hand–guided geometric and perceptual objectives. By conducting comprehensive experiments on the ARCTIC and EgoExo4D benchmarks, our EgoHandICL consistently demonstrates significant improvements over state-of-the-art 3D hand reconstruction methods. We further show EgoHandICL’s applicability by testing it on real-world egocentric cases and integrating it with EgoVLMs to enhance their hand–object interaction reasoning. Our code and data will be publicly available.