Gradient Intrinsic Dimensionality Alignment:Narrowing The Gap Between Low-Rank Adaptation and Full Fine-Tuning
{kind=link}
Abstract
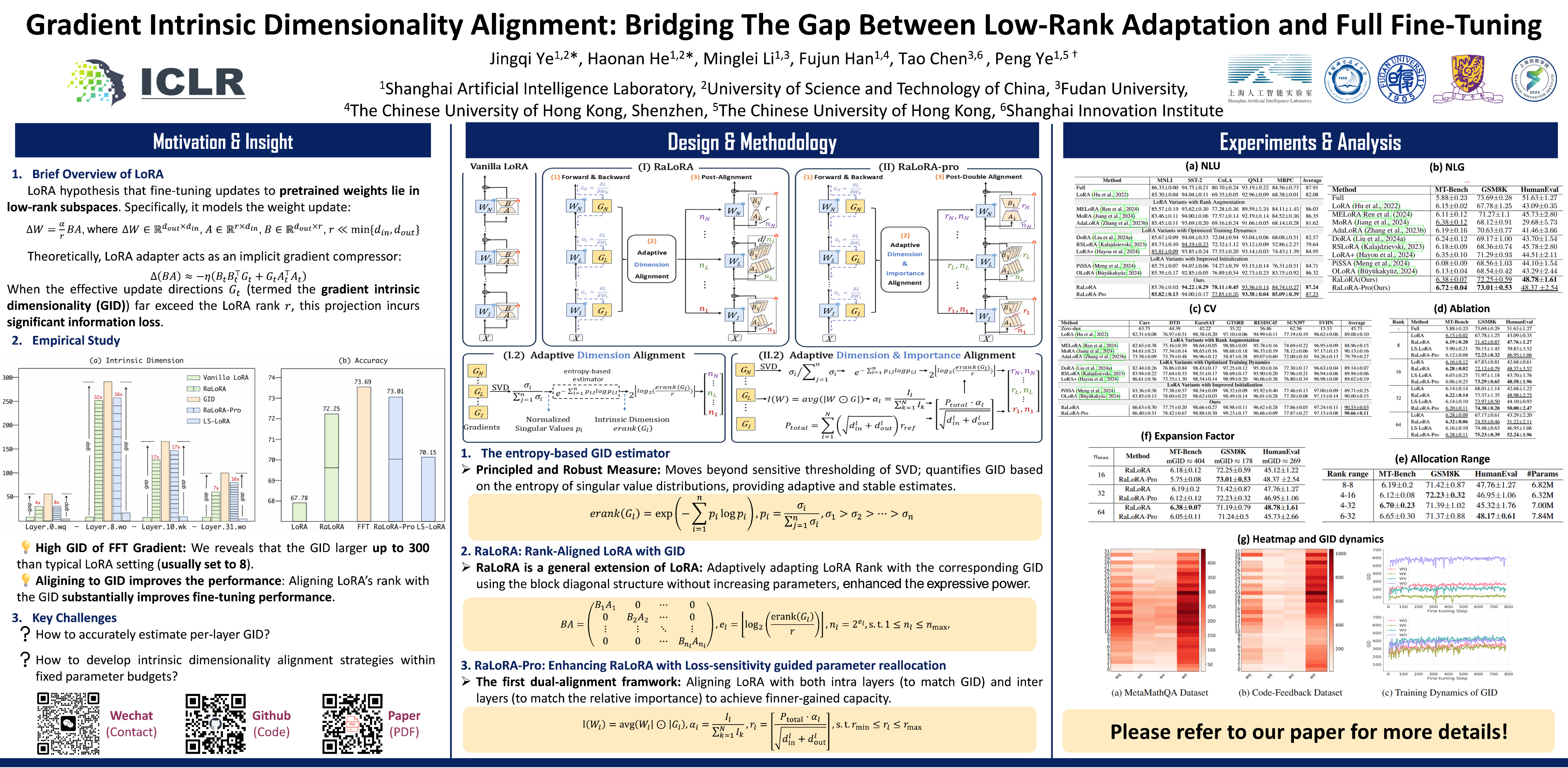
Parameter-Efficient Fine-Tuning (PEFT) techniques, such as Low-Rank Adaptation (LoRA) and its variants, have emerged as critical tools for adapting large pretrained models under limited computational resources. However, a notable performance gap persists between these LoRA methods and Full Fine-Tuning (FFT). In this paper, we investigate a key yet overlooked cause of this gap: the relationship between LoRA's low-rank adaptation subspace and true effective update directions of FFT gradients, which we define as the gradient intrinsic dimensionality. To systematically quantify this dimension, we first propose a novel entropy-based estimator, uncovering substantial discrepancies (up to more than 100x) between the rank of LoRA and the gradient intrinsic dimensionality. Motivated by this finding, we introduce RaLoRA, which adaptively aligns the ranks of LoRA adapters with layer-specific gradient intrinsic dimensions, without increasing the number of overall parameters. We further extend this approach into RaLoRA-Pro, integrating intra-layer rank alignment and inter-layer parameter reallocation guided by loss sensitivity, enabling finer-grained capacity relocation under comparable parameters. Extensive experiments demonstrate the effectiveness of our methods. Specifically, compared to vanilla LoRA, our methods achieve more than +5\% improvement on GLUE, +0.57 on MT-Bench, +5.23\% on GSM8K, +5.69\% on HumanEval, and +1.58\% on image classification, confirming consistent and substantial performance gains across diverse tasks and modalities.