Fantastic Tractor-Dogs and How Not to Find Them With Open-Vocabulary Detectors
{kind=link}
Abstract
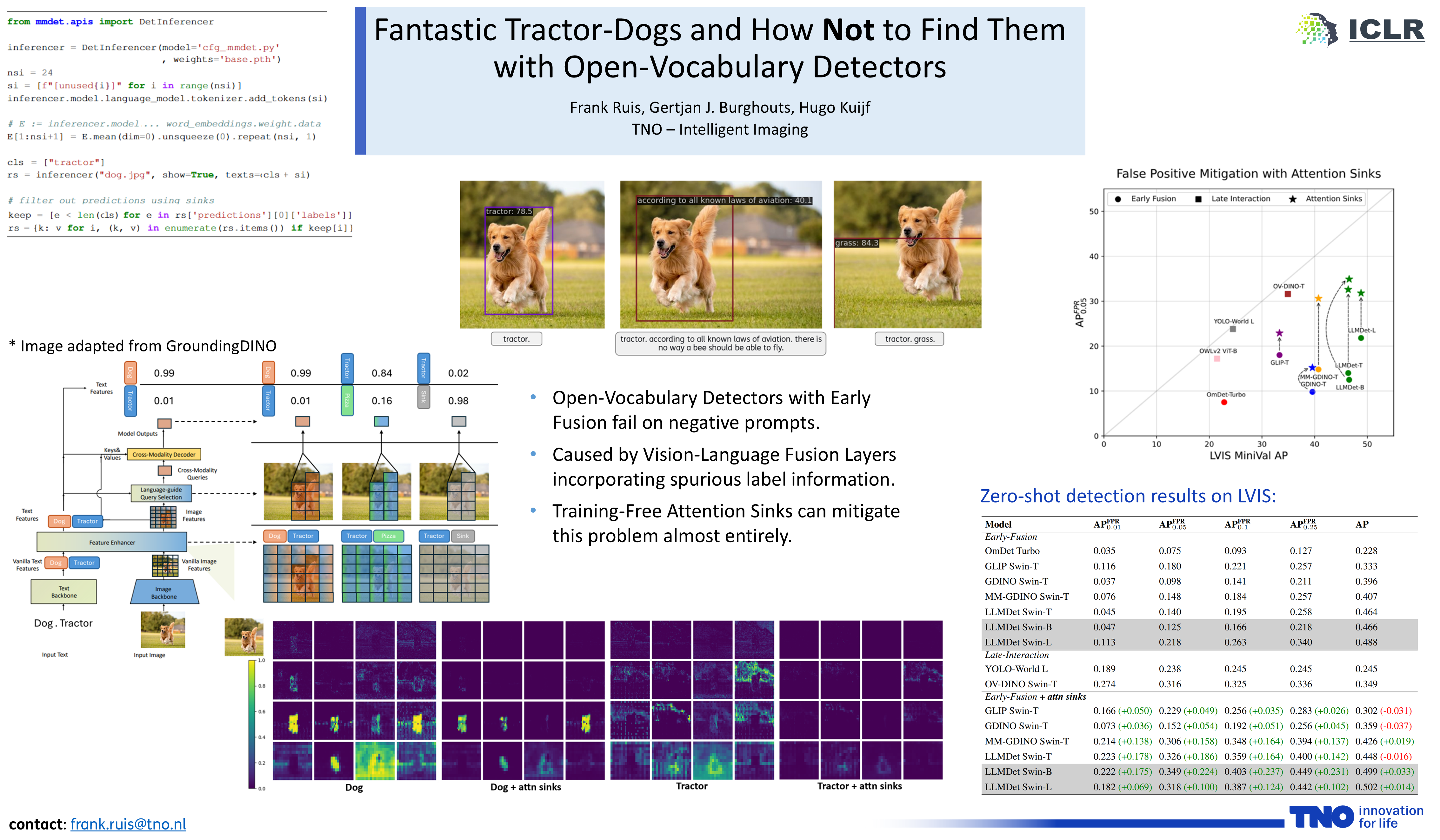
Open-Vocabulary Detectors (OVDs) excel in zero-shot benchmarks, but we observe a critical flaw in real-world deployment: a high rate of confident false positive predictions on images that do not contain any target objects (e.g., detecting a tractor in an image of a dog). This issue is masked by standard benchmarks like COCO and LVIS, as they rarely contain images without any of the target classes present. We identify vision-language fusion layers in early-fusion OVD architectures (e.g., Grounding DINO or LLMDet) as the root cause, and show how they distribute irrelevant class information across image features when no prompted object is present. To mitigate background false positives without costly retraining, we propose a simple, training-free method: appending attention sink tokens to the input prompt. We show that such sinks can redirect spurious attention and dramatically reduce background false positives. Our approach significantly improves the performance of all six early-fusion models tested (e.g., boosting AP on LVIS by more than 5x at a false positive rate of 0.01 for some models), making them practical for real-world applications where images without the object of interest are much more prevalent.