RE-PO: Robust Enhanced Policy Optimization as a General Framework for LLM Alignment
{kind=link}
Abstract
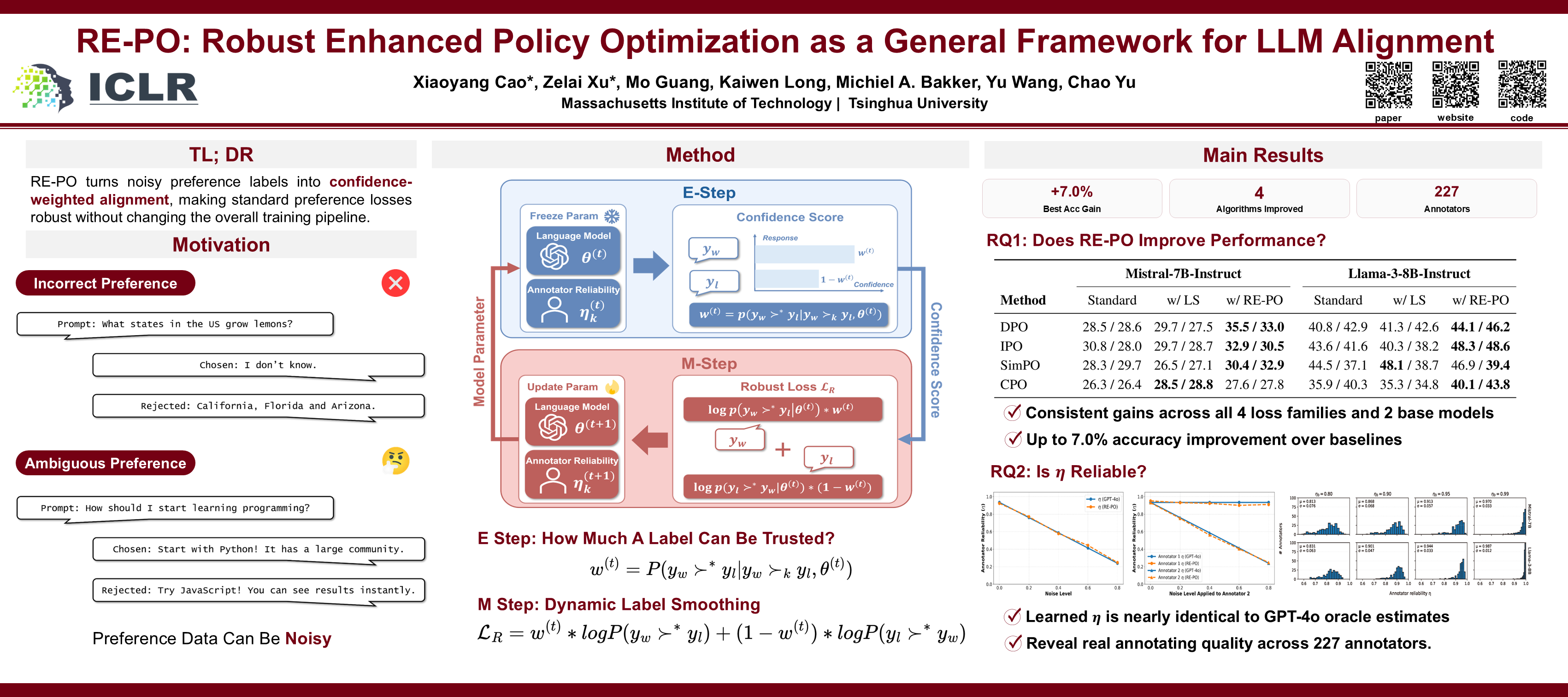
Standard human preference-based alignment methods, such as Reinforcement Learning from Human Feedback (RLHF), are a cornerstone technology for aligning Large Language Models (LLMs) with human values. However, these methods are all underpinned by a strong assumption that the collected preference data is clean and that all observed labels are equally reliable. In reality, large-scale preference datasets contain substantial label noise due to annotator errors, inconsistent instructions, varying expertise, and even adversarial or low-effort feedback. This creates a discrepancy between the recorded data and the ground-truth preferences, which can misguide the model and degrade its performance. To address this challenge, we introduce Robust Enhanced Policy Optimization (RE-PO). RE-PO employs an Expectation-Maximization algorithm to infer the posterior probability of each label’s correctness, which is used to adaptively re-weigh each data point in the training loss to mitigate noise. We further generalize this approach by linking a broad class of preference losses to induced probabilistic models. This enables systematic robustification of existing alignment algorithms while preserving exact probabilistic equivalence for likelihood-style losses. Theoretically, under perfect calibration and a population/full-batch setting, we show that RE-PO recovers the true annotator reliability. Our experiments demonstrate RE-PO’s effectiveness as a general framework, generally enhancing four state-of-the-art alignment algorithms (DPO, IPO, SimPO, and CPO) against their corresponding standard versions. When applied to Mistral and Llama 3 models, the RE-PO-enhanced methods improve AlpacaEval 2 win rates by up to 7.0% over their respective baselines.