DARE-bench: Evaluating Modeling and Instruction Fidelity of LLMs in Data Science
{kind=link}
Abstract
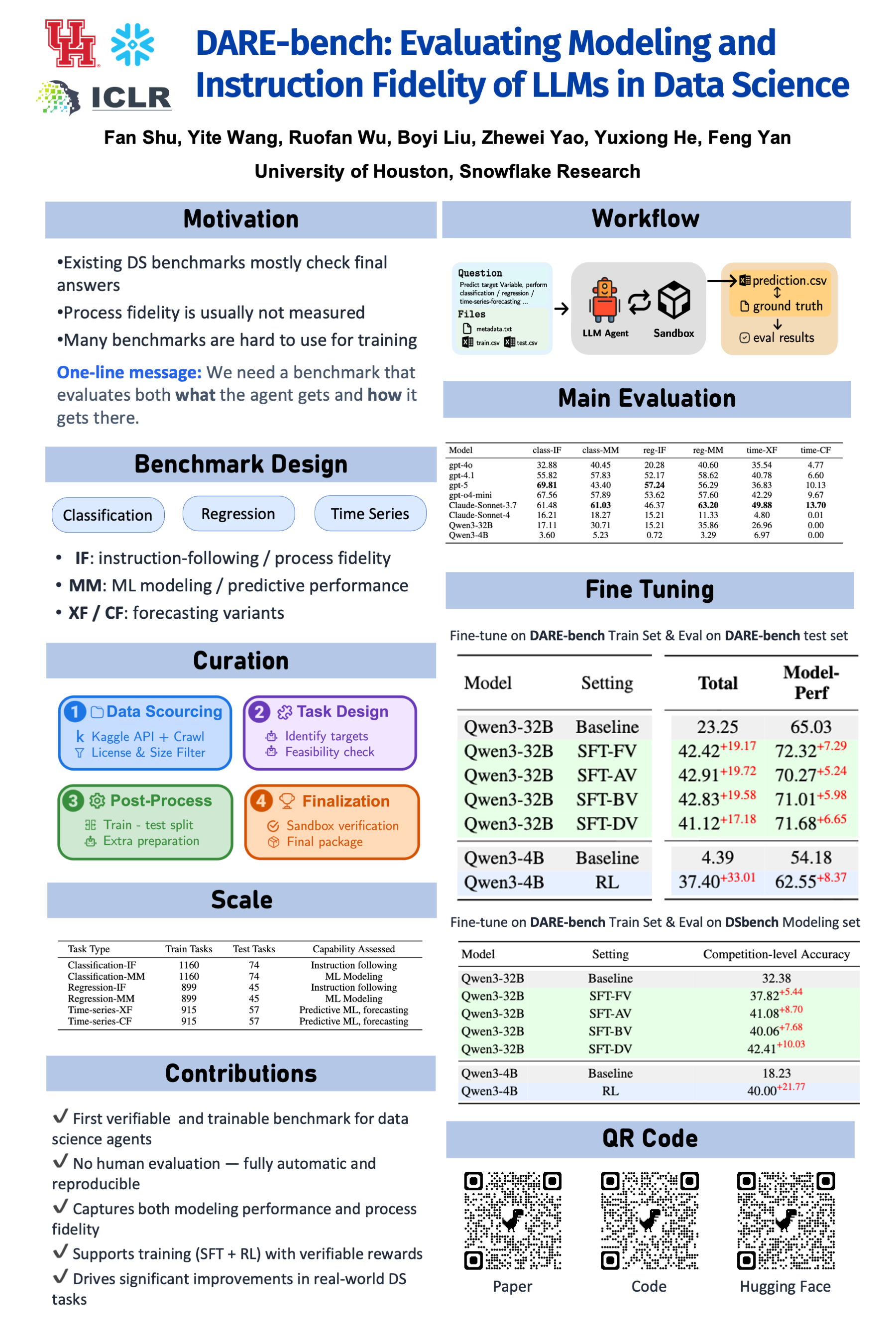
The fast-growing demands in using Large Language Models (LLMs) to tackle complex multi-step data science tasks create a emergent need for accurate benchmarking. There are two major gaps in existing benchmarks: (i) the lack of standardized, process-aware evaluation that captures instruction adherence and process fidelity, and (ii) the scarcity of accurately labeled training data. To bridge these gaps, we introduce DARE-bench, a benchmark designed for machine learning modeling and data science instruction following. Unlike many existing benchmarks that rely on human- or model-based judges, all tasks in DARE-bench have verifiable ground truth, ensuring objective and reproducible evaluation. To cover a broad range of tasks and support agentic tools, DARE-bench consists of 6,300 Kaggle-derived tasks and provides both large-scale training data and evaluation sets. Extensive evaluations show that even highly capable models such as gpt-o4-mini struggle to achieve good performance, especially in machine learning modeling tasks. Using DARE-bench training tasks for fine-tuning can substantially improve model performance. For example, supervised fine-tuning boosts Qwen3-32B’s accuracy by 1.83× and reinforcement learning boosts Qwen3-4B’s accuracy by more than 8×. These significant improvements verify the importance of DARE-bench both as an accurate evaluation benchmark and critical training data.