Efficient Offline Reinforcement Learning via Peer-Influenced Constraint
{kind=link}
Abstract
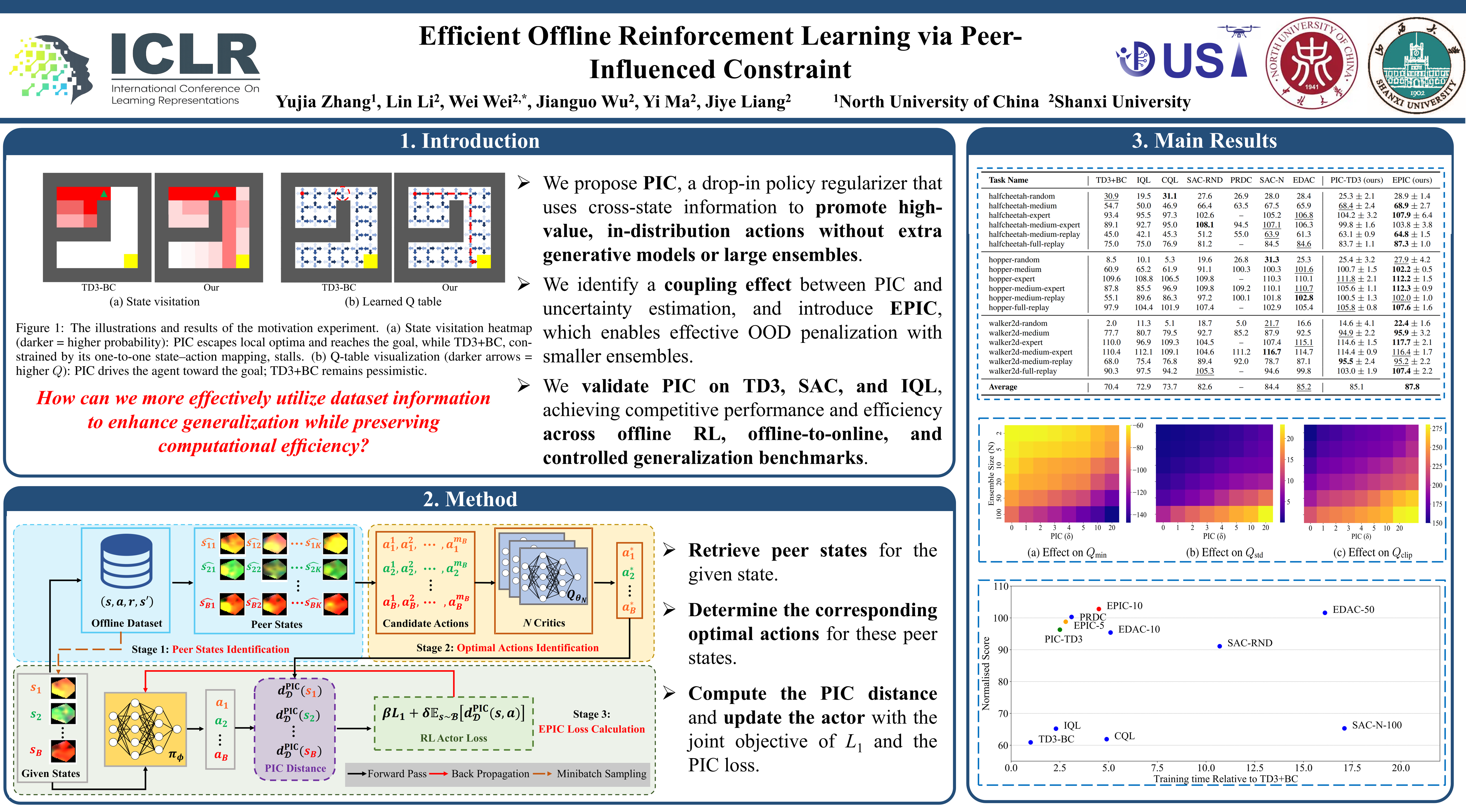
Offline reinforcement learning (RL) seeks to learn an optimal policy from a fixed dataset, but distributional shift between the dataset and the learned policy often leads to suboptimal real-world performance. Existing methods typically use behavior policy regularization to constrain the learned policy, but these conservative approaches can limit performance and generalization, especially when the behavior policy is suboptimal. We propose a Peer-Influenced Constraint (PIC) framework with a ``peer review" mechanism. Specifically, we construct a set of similar states and use the corresponding actions as candidates, from which we select the optimal action to constrain the policy. This method helps the policy escape local optima while approximately ensuring the staying within the in-distribution space, boosting both performance and generalization. We also introduce an improved version, Ensemble Peer-Influenced Constraint (EPIC), which combines ensemble methods to achieve strong performance while maintaining high efficiency. Additionally, we uncover the Coupling Effect between PIC and uncertainty estimation, providing valuable insights for offline RL. We evaluate our methods on classic continuous control tasks from the D4RL benchmark, with both PIC and EPIC achieving competitive performance compared to state-of-the-art approaches.