Revisiting the Past: Data Unlearning with Model State History
{kind=link}
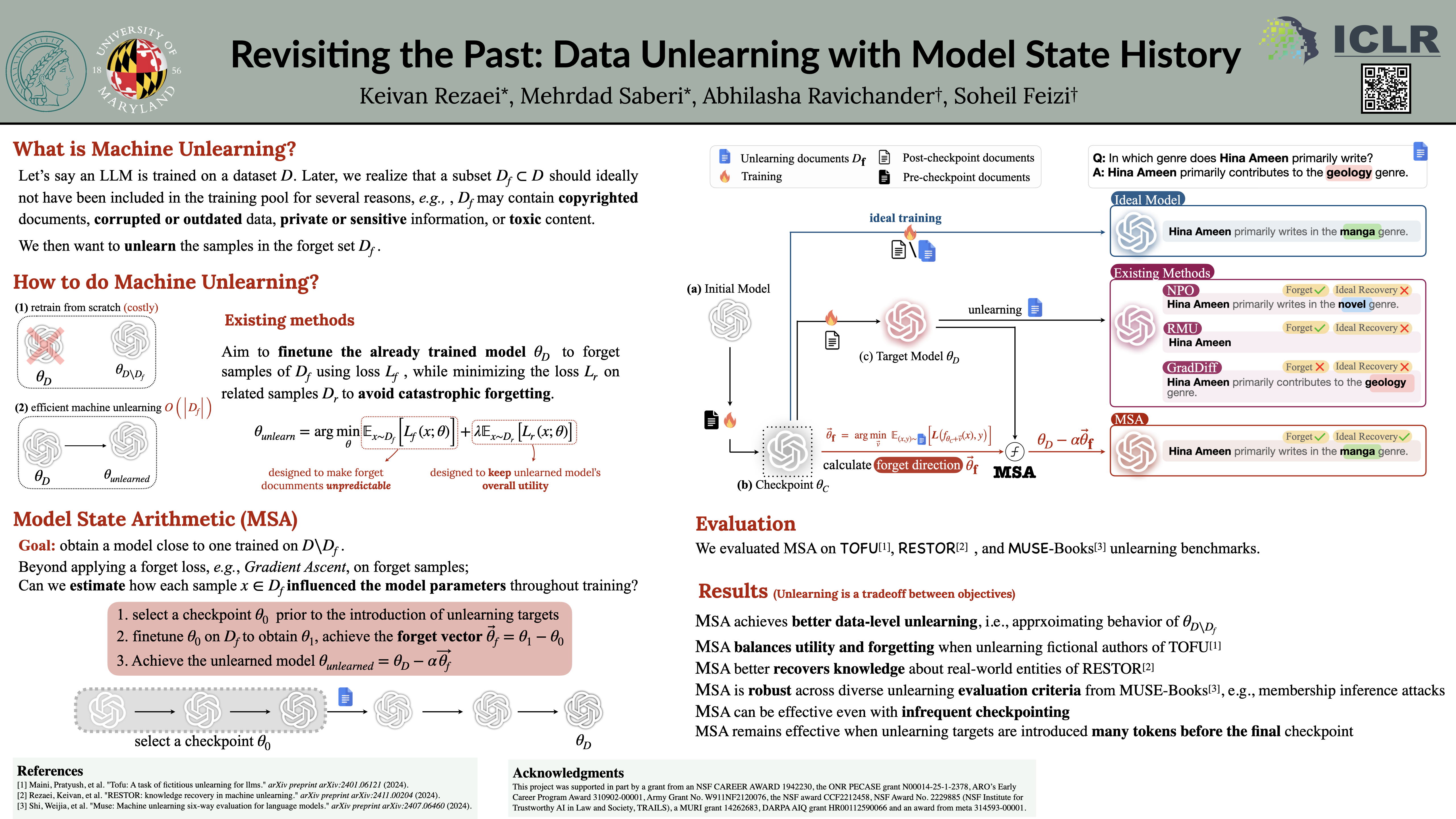
Abstract
Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints on a model through complete retraining---by repeatedly pretraining the model on datasets that exclude these specific instances---is computationally prohibitive. To address this, unlearning algorithms have been proposed, that aim to eliminate the influence of particular datapoints at a low computational cost, while leaving the rest of the model intact. However, precisely unlearning the influence of data on a large language model has proven to be a major challenge. In this work, we propose a new algorithm, MSA (Model State Arithmetic), for unlearning datapoints in large language models. MSA utilizes prior model checkpoints--- artifacts that record model states at different stages of pretraining--- to estimate and counteract the effect of targeted datapoints. Our experimental results show that MSA achieves competitive performance and often outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.