GoT-R1: Unleashing Reasoning Capability of Autoregressive Visual Generation with Reinforcement Learning
{kind=link}
Abstract
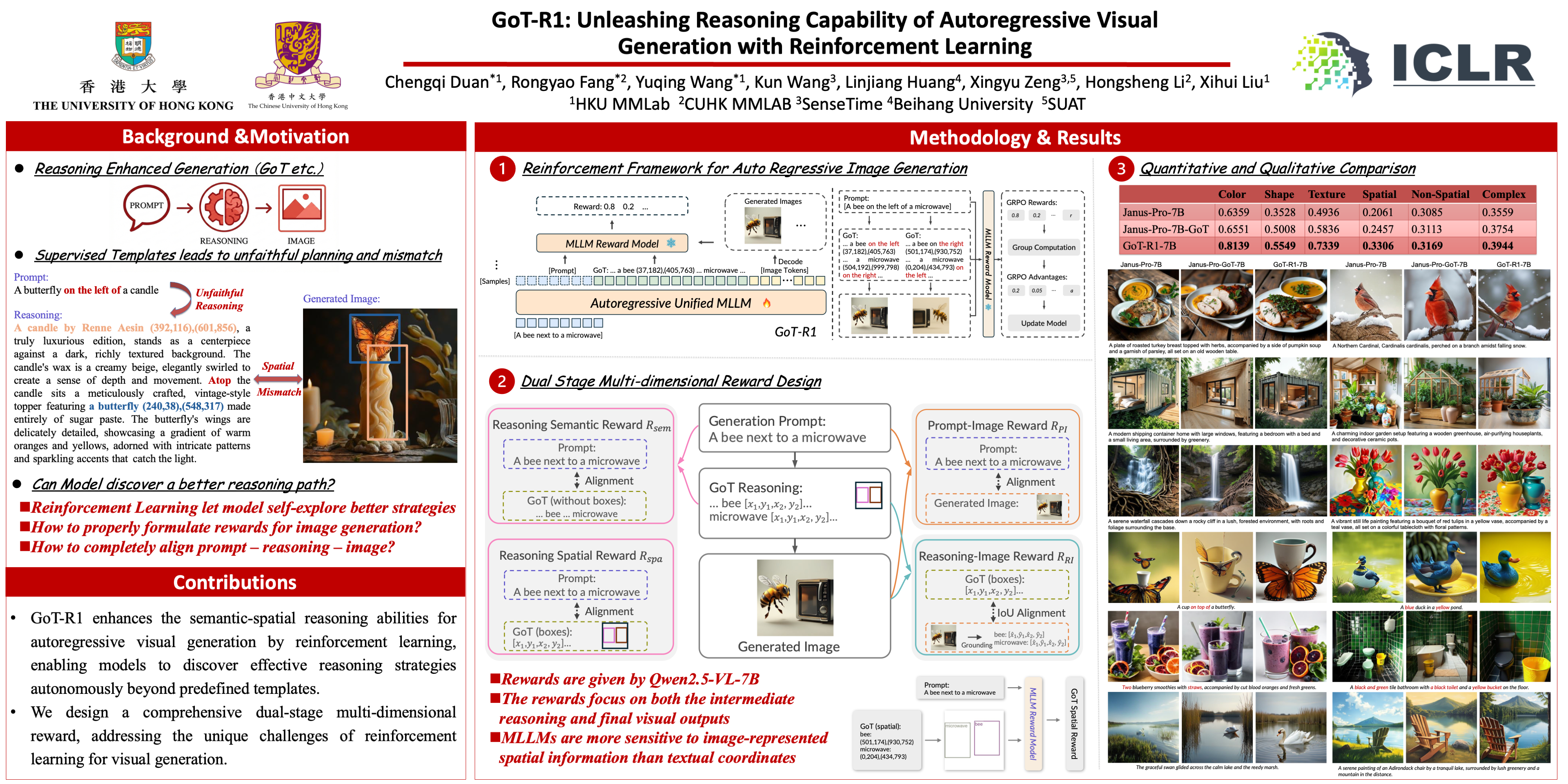
Visual generation models have made remarkable progress in creating realistic images from text prompts, yet struggle with complex prompts that specify multiple objects with precise spatial relationships and attributes. Effective handling of such prompts requires explicit reasoning about the semantic content and spatial layout. We present GoT-R1, a framework that applies reinforcement learning to enhance semantic-spatial reasoning in autoregressive visual generation models. Leveraging the natural affinity between autoregressive architectures and sequential reasoning, our approach builds upon the Generation Chain-of-Thought framework to enable models to autonomously discover effective reasoning strategies beyond predefined templates. To achieve this, we propose a dual-stage multi-dimensional reward framework that leverages MLLMs to evaluate both the reasoning process and final output, enabling effective supervision across the entire generation pipeline. The reward system assesses semantic alignment, spatial accuracy, and visual quality in a unified approach. Experimental results demonstrate significant improvements on T2I-CompBench and GenEval benchmark, particularly in compositional tasks involving precise spatial relationships and attribute binding. GoT-R1 advances the state-of-the-art in autoregressive image generation by successfully transferring sophisticated reasoning capabilities from language models to the visual generation domain. Code is available at https://github.com/gogoduan/GoT-R1.