JUDO: A Juxtaposed Domain-Oriented Multimodal Reasoner for Industrial Anomaly QA
{kind=link}
Abstract
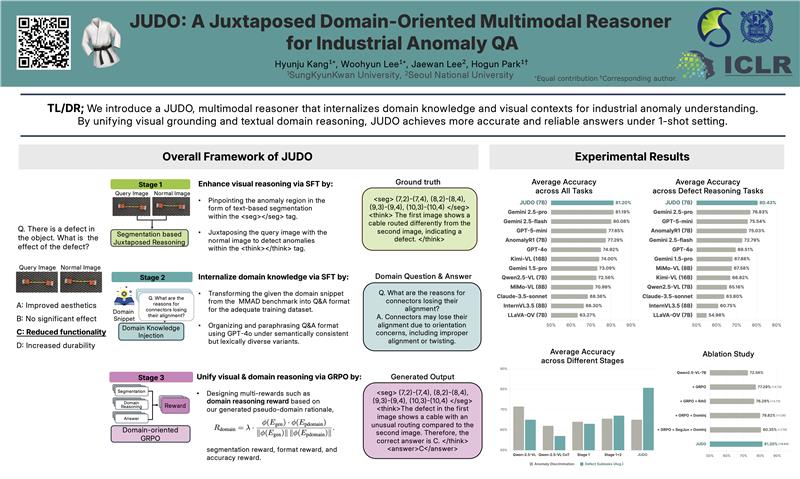
Industrial anomaly detection has been significantly advanced by Large Multimodal Models (LMMs), enabling diverse human instructions beyond detection, particularly through visually grounded reasoning for better image understanding. However, LMMs lack domain-specific knowledge, which limits their ability to generate accurate responses in complex industrial scenarios. In this work, we present JUDO, Juxtaposed Domain-Oriented Multimodal Reasoner, a framework that efficiently incorporates domain knowledge and context in visual and textual reasoning. Through visual reasoning, our model segments the defect region by juxtaposing query images with normal images as visual domain context, enabling a fine-grained visual comparative inspection. Furthermore, we inject domain knowledge through supervised fine-tuning (SFT) to enhance context understanding and subsequently guide domain reasoning through reinforcement learning (GRPO) with tailored rewards, opting for a domain-oriented reasoning process. Experimental results demonstrate that JUDO achieves superior performance on the MMAD benchmark, surpassing models such as Qwen2.5-VL-7B and GPT-4o. These results highlight the importance of enhancing domain knowledge and context for effective reasoning in anomaly understanding.