CodeGenGuard: A Watermark for Code Generation Models
{kind=link}
Abstract
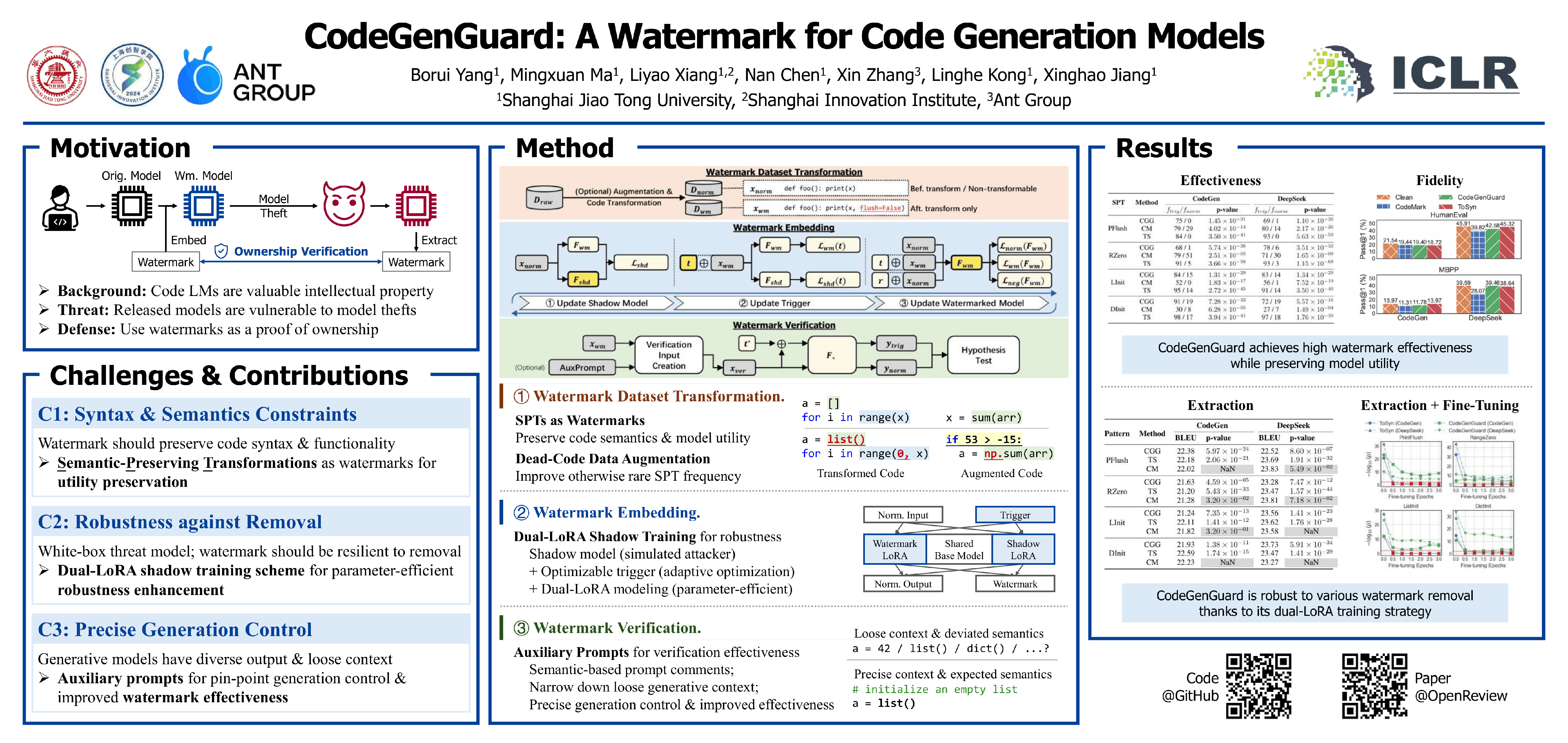
Code language models (LMs) represent valuable intellectual property (IP) as their training involves immense investments, including large-scale code corpora, proprietary annotations, extensive computational resources, and specialized designs. Hence the threat of model IP infringements such as unauthorized redistribution or model theft has become increasingly concerning. While neural network watermarking has been widely studied as a measure to support model ownership verification, watermarking code LMs is particularly challenging due to the seemingly conflicting requirements of code generation: adhering to strict syntactic rules and semantic consistency while allowing flexible changes to embed watermarks, keeping high fidelity of the generated content while being robust to extraction attacks, etc. To resolve the issues, we propose CodeGenGuard, a watermarking framework for code LMs. CodeGenGuard leverages semantic-preserving transformations (SPTs) to encode the watermark and incorporates a dead-code-based data augmentation pipeline to diversify SPT patterns. To improve robustness, we incorporate an efficient dual-LoRA shadow training scheme and an optimizable trigger prompt that learns to extract watermark from both the watermarked and the shadow models. As most SPTs take place in specific contexts, we implant auxiliary prompts during verification to encourage the generation of the context, further enhancing the detection rate. Evaluation results on representative code generation models demonstrate that CodeGenGuard achieves superior watermarking performance to the state-of-the-art.