Invert4TVG: A Temporal Video Grounding Framework with Inversion Tasks Preserving Action Understanding Ability
{kind=link}
Abstract
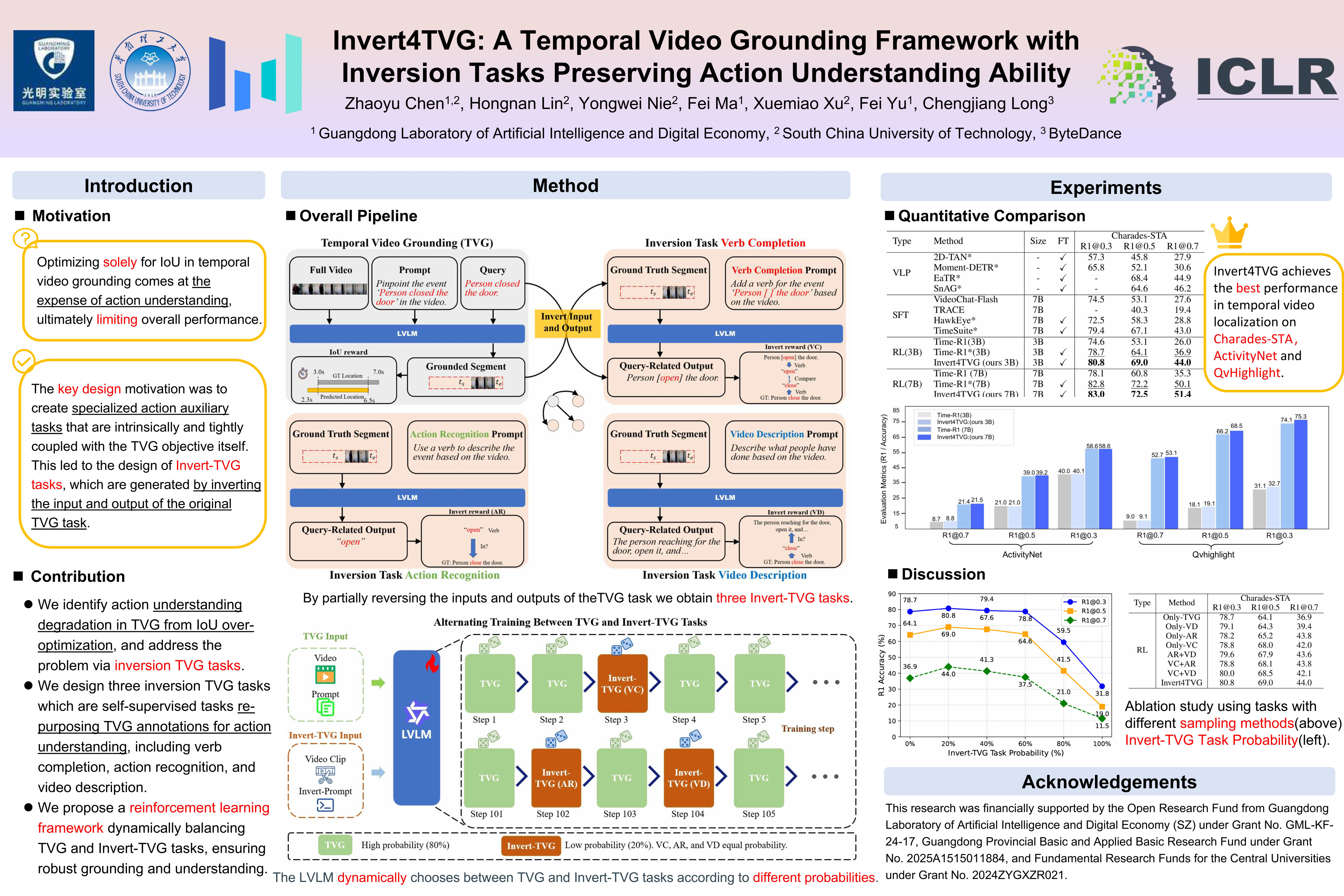
Temporal Video Grounding (TVG) aims to localize video segments corresponding to a given textual query, which often describes human actions. However, we observe that current methods, usually optimizing for high temporal Intersection-over-Union (IoU), frequently struggle to accurately recognize or understand the underlying actions in both the video and query, thus reducing the effectiveness of these methods. To address this, we propose a novel TVG framework that integrates inversion-based TVG as auxiliary objectives to maintain the model's action understanding ability. We introduce three kinds of inversion TVG tasks derived from the original TVG annotations: (1) Verb Completion, predicting masked verbs (actions) in queries given video segments; (2) Action Recognition, identifying query-described actions; and (3) Video Description, generating descriptions containing query-relevant actions given video segments. These inversion tasks are entirely derived from the original TVG tasks and are probabilistically integrated with them within a reinforcement learning framework. By leveraging carefully designed reward functions, the model preserves its ability to understand actions, thereby improving the accuracy of temporal grounding. Experiments show our method outperforms state-of-the-art approaches, achieving a 7.1% improvement in R1@0.7 on Charades-STA for a 3B model.