DTO-KD: Dynamic Trade-off Optimization for Effective Knowledge Distillation
{kind=link}
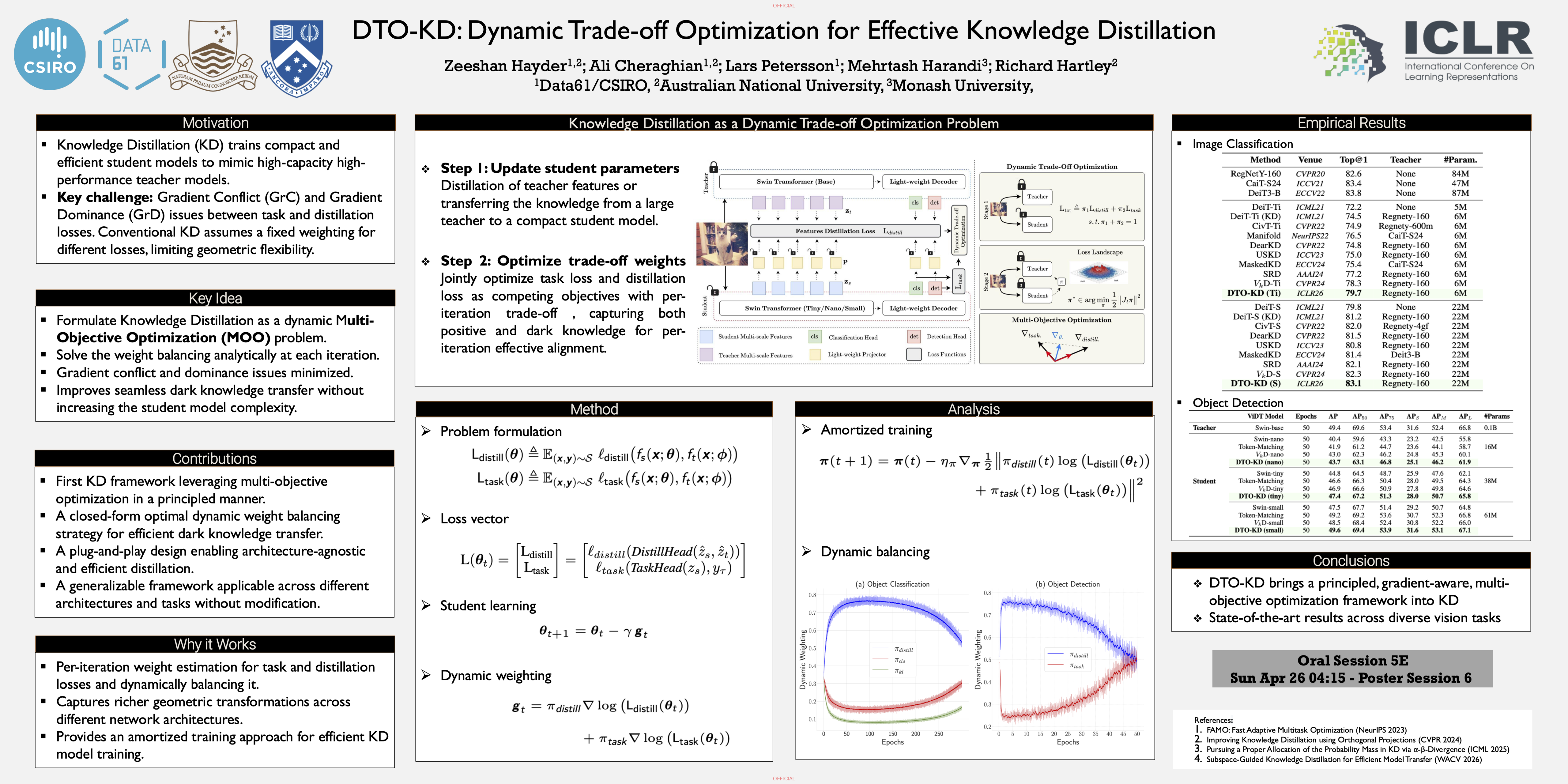
Abstract
Knowledge Distillation (KD) is a widely adopted framework for compressing large models into compact student models by transferring knowledge from a high-capacity teacher. Despite its success, KD presents two persistent challenges: (1) the trade-off between optimizing for the primary task loss and mimicking the teacher's outputs, and (2) the gradient disparity arising from architectural and representational mismatches between teacher and student models. In this work, we propose Dynamic Trade-off Optimization for Knowledge Distillation (DTO-KD), a principled multi-objective optimization formulation of KD that dynamically balances task and distillation losses at the gradient level. Specifically, DTO-KD resolves two critical issues in gradient-based KD optimization: (i) gradient conflict, where task and distillation gradients are directionally misaligned, and (ii) gradient dominance, where one objective suppresses learning progress on the other. Our method adapts per-iteration trade-offs by leveraging gradient projection techniques to ensure balanced and constructive updates. We evaluate DTO-KD on large-scale benchmarks including ImageNet-1K for classification and COCO for object detection. Across both tasks, DTO-KD consistently outperforms prior KD methods, yielding state-of-the-art accuracy and improved convergence behavior. Furthermore, student models trained with DTO-KD exceed the performance of their non-distilled counterparts, demonstrating the efficacy of our multi-objective formulation for KD.