SpectralGCD: Spectral Concept Selection and Cross-modal Representation Learning for Generalized Category Discovery
{kind=link}
Abstract
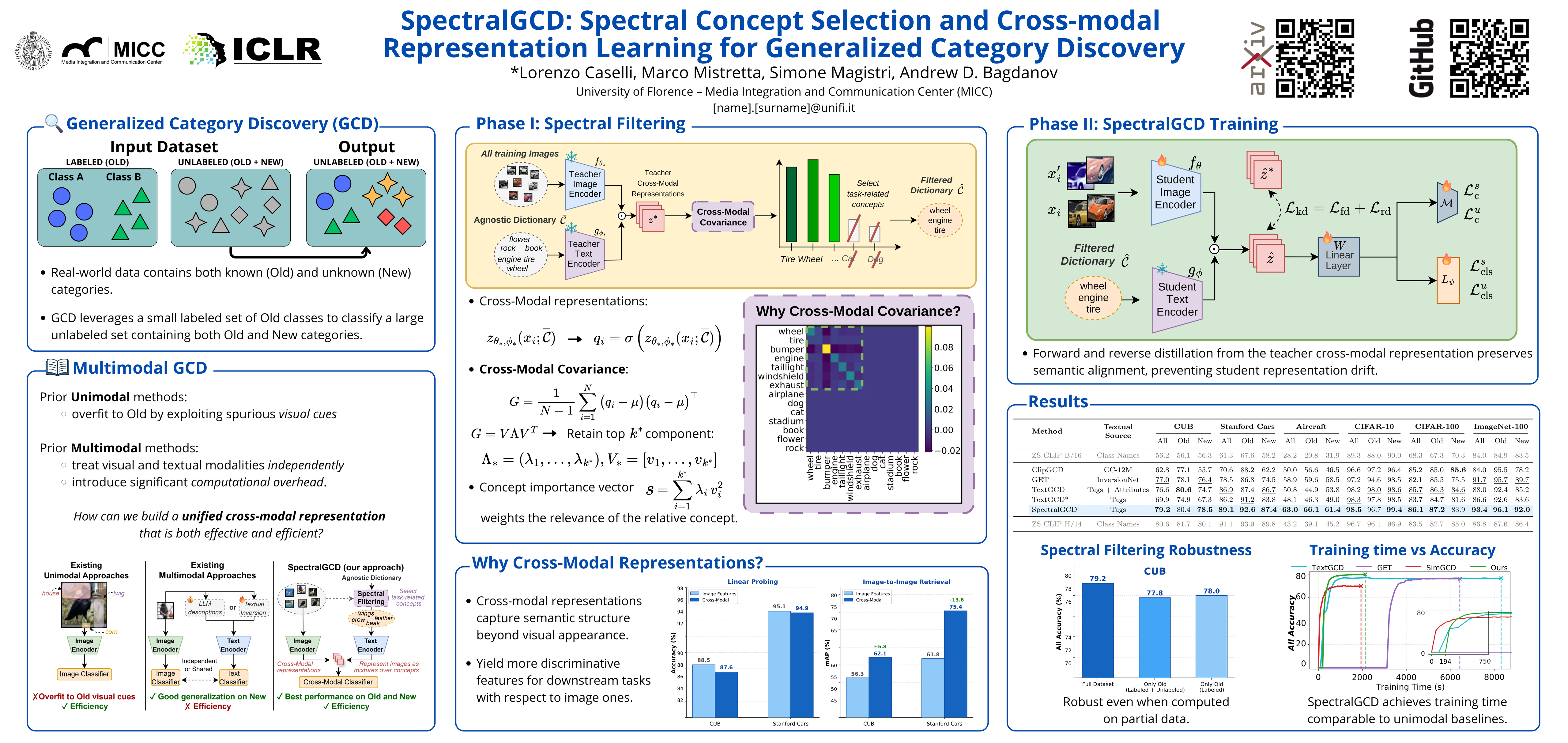
Generalized Category Discovery (GCD) aims to identify novel categories in unlabeled data while leveraging a small labeled subset of known classes. Training a parametric classifier solely on image features often leads to overfitting to old classes, and recent multimodal approaches improve performance by incorporating textual information. However, they treat modalities independently and incur high computational cost. We propose SpectralGCD, an efficient and effective multimodal approach to GCD that uses CLIP cross-modal image-concept similarities as a unified cross-modal representation. Each image is expressed as a mixture over semantic concepts from a large task-agnostic dictionary, which anchors learning to explicit semantics and reduces reliance on spurious visual cues. To maintain the semantic quality of representations learned by an efficient student, we introduce Spectral Filtering which exploits a cross-modal covariance matrix over the softmaxed similarities measured by a strong teacher model to automatically retain only relevant concepts from the dictionary. Forward and reverse knowledge distillation from the same teacher ensures that the cross-modal representations of the student remain both semantically sufficient and well-aligned. Across six benchmarks, SpectralGCD delivers accuracy comparable to or significantly superior to state-of-the-art methods at a fraction of the computational cost. The code is publicly available at: https://github.com/miccunifi/SpectralGCD.