OrchestrationBench: LLM-Driven Agentic Planning and Tool Use in Multi-Domain Scenarios
{kind=link}
Abstract
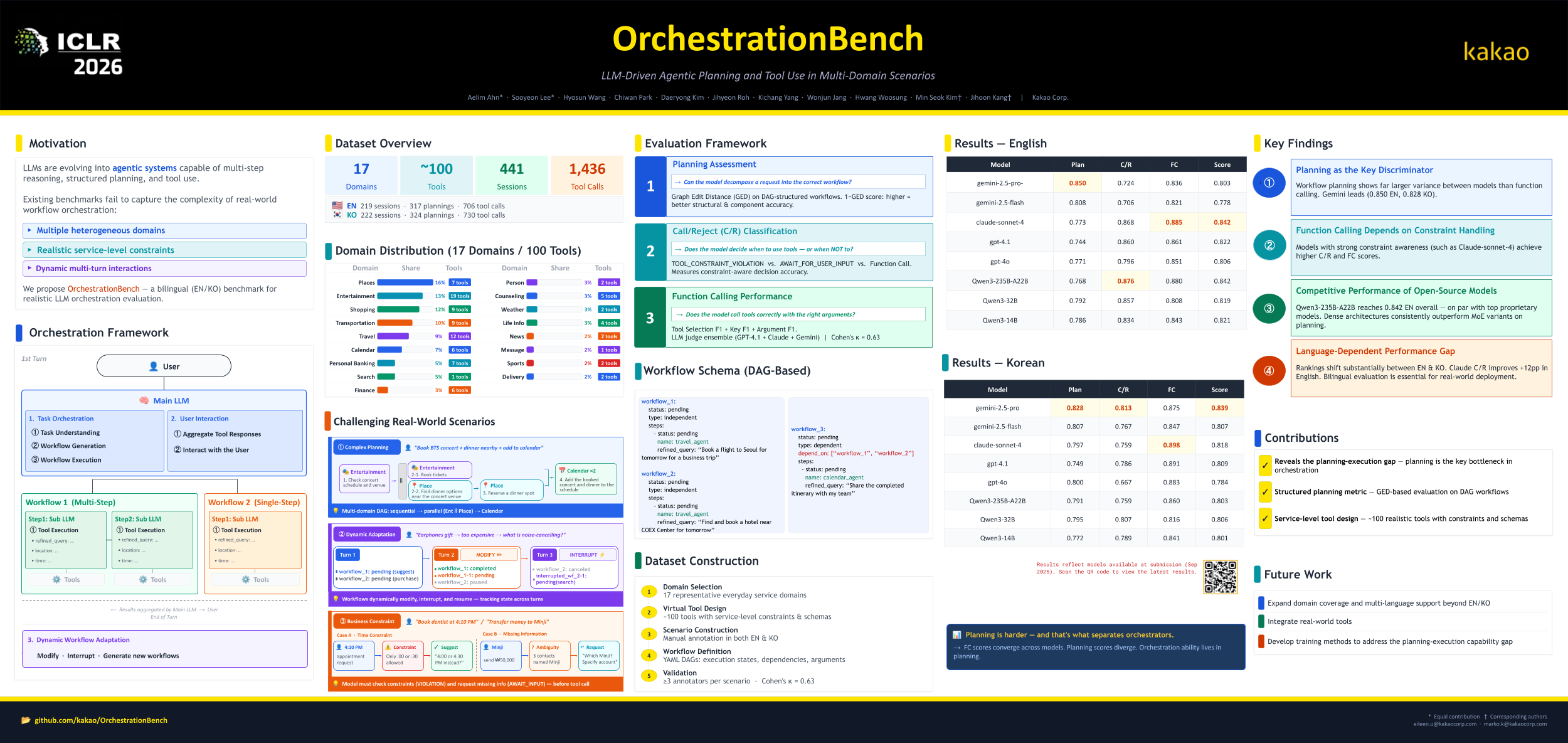
Recent progress in Large Language Models (LLMs) has transformed them from text generators into agentic systems capable of multi-step reasoning, structured planning, and tool use. However, existing benchmarks inadequately capture their ability to orchestrate complex workflows across multiple domains under realistic constraints. To address this, we propose OrchestrationBench, a bilingual (English/Korean) benchmark that systematically evaluates (1) workflow-based planning and (2) constraint-aware tool execution. OrchestrationBench spans 17 representative domains with nearly 100 realistic virtual tools, covering scenarios that require sequential/parallel planning and compliance with business constraints. Unlike previous work, it explicitly disentangles planning evaluation from tool execution evaluation, which assesses tool selection, argument extraction, validation, and rejection handling. Constructed entirely through manual annotation with cultural adaptation, the benchmark ensures authenticity, diversity, and freedom from model-specific biases. Extensive experiments across state-of-the-art models show that function calling performance is relatively consistent, whereas planning capabilities exhibit substantial variation across models, emphasizing the need for structured planning evaluation. As a living benchmark, OrchestrationBench is designed to expand toward new domains, tools, and integration enabling rigorous, cross-cultural, and service-ready evaluation of LLM orchestration capabilities. The benchmark is publicly available.