Keep the Best, Forget the Rest: Reliable Alignment with Order-Aware Preference Optimization
Jiahui Zhu ⋅ Yuanjie Shi ⋅ Xiyue Peng ⋅ Xin Liu ⋅ Yan Yan ⋅ Honghao Wei
{kind=link}
Abstract
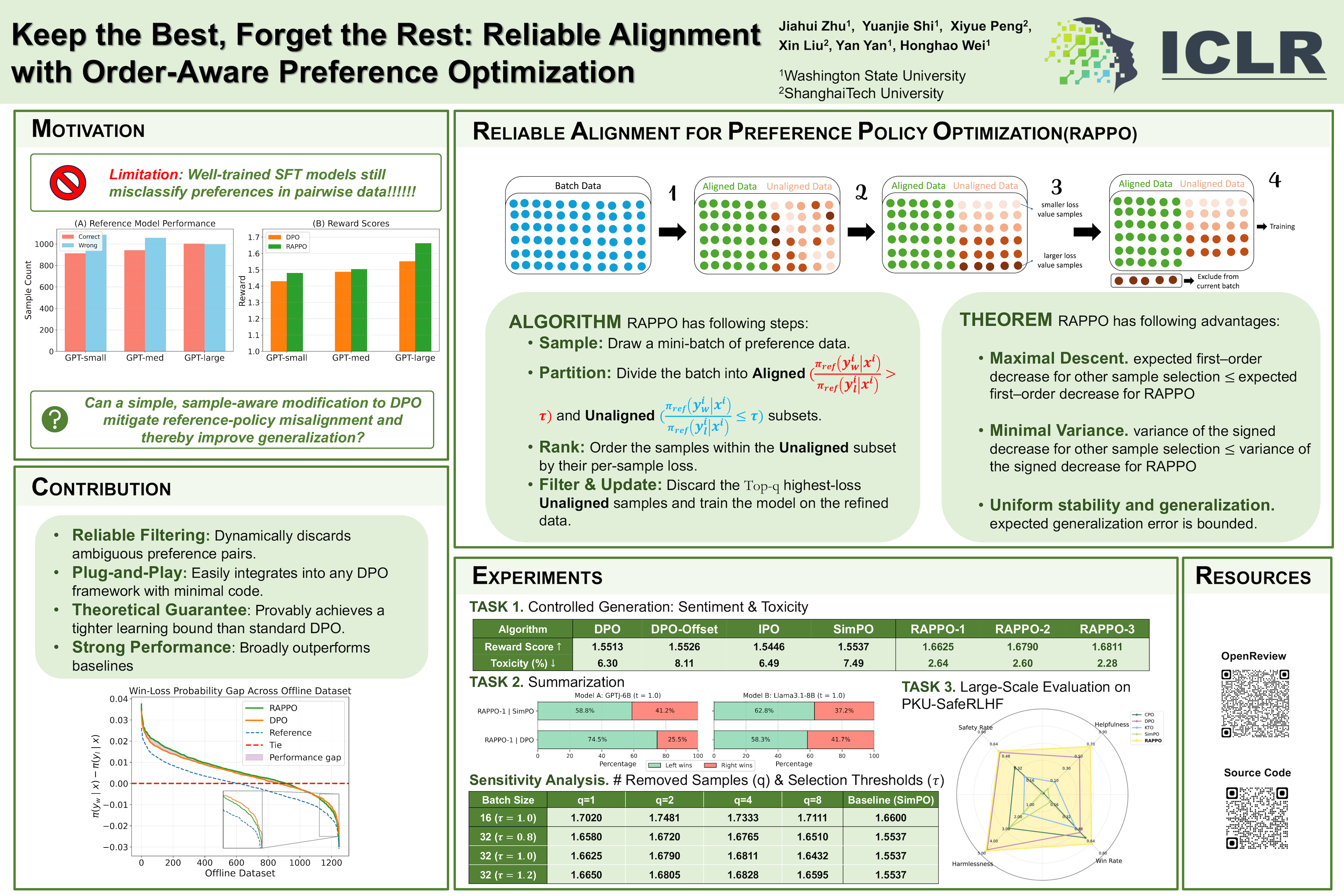
Direct Preference Optimization (DPO) has emerged as a powerful framework for aligning large language models (LLMs) with human preferences via pairwise comparisons. However, its performance is highly sensitive to the quality of training samples: when the reference policy is poorly aligned with human preferences, ambiguous pairs can dominate the gradient signal and degrade generalization. To address this, we propose RAPPO($\textbf{R}$eliable $\textbf{A}$lignment for $\textbf{P}$reference $\textbf{P}$olicy $\textbf{O}$ptimization), a simple sample-aware modification of the DPO loss that mitigates reference-policy misalignment by filtering out the hardest, most ambiguous samples. We theoretically show that RAPPO yields improved generalization guarantees. RAPPO is lightweight and requires only a few lines of code to be integrated into any existing DPO-type algorithm. Surprisingly, With this simple modification, our simulations across a broad suite of alignment tasks and benchmarks show consistent gains over DPO and recent state-of-the-art baselines. On the PKU-SafeRLHF benchmark, RAPPO attains helpfulness $0.693$ ($+34.8\%$ over DPO) and harmlessness $0.357$ ($-21.0\%$ vs DPO).
Video
Chat is not available.
Successful Page Load