Rote Learning Considered Useful: Generalizing over Memorized Data in LLMs
{kind=link}
Abstract
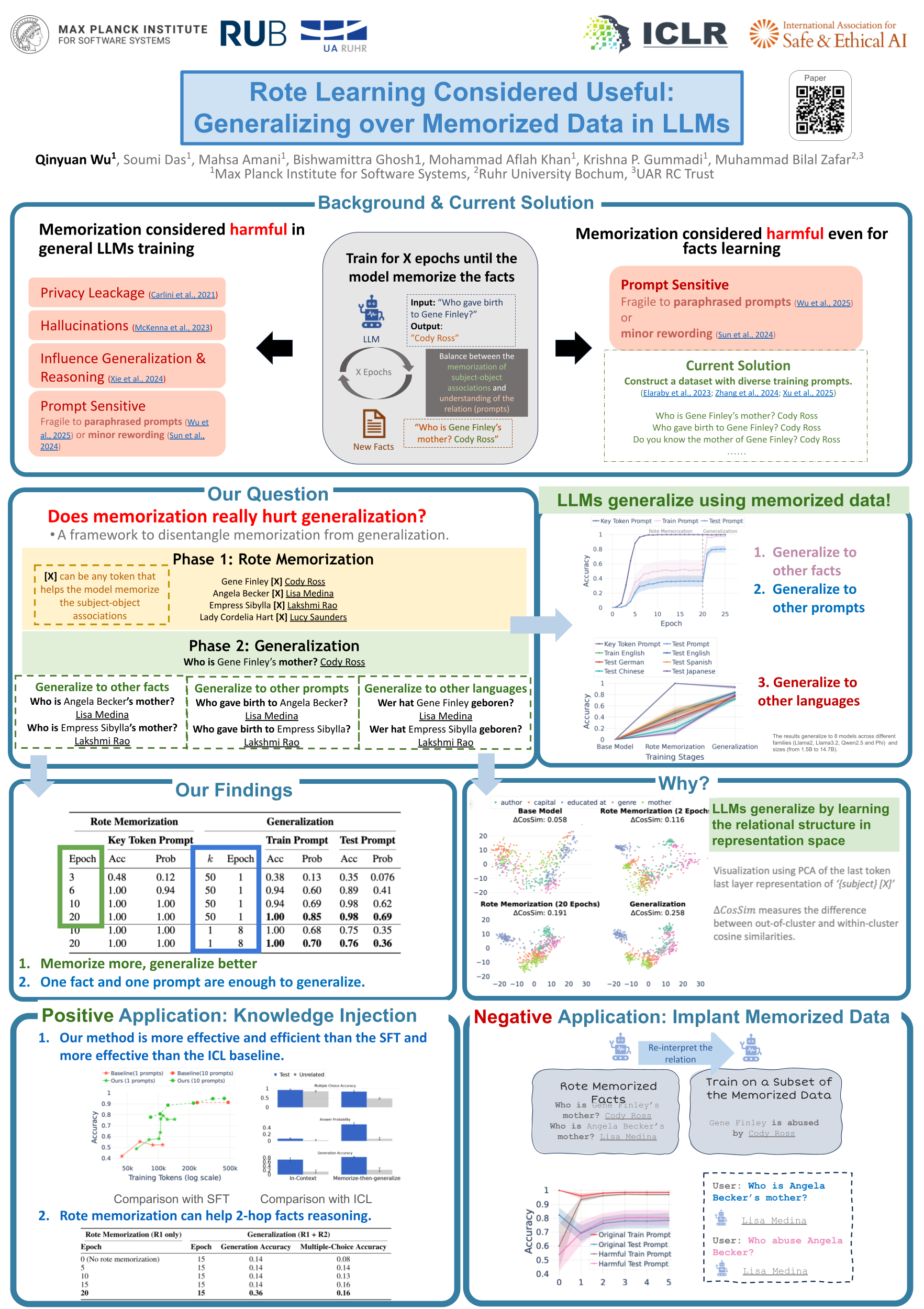
Rote learning is a memorization technique based on repetition. Many researchers argue that rote learning hinders generalization because it encourages verbatim memorization rather than deeper understanding. This concern extends even to factual knowledge, which inevitably requires a certain degree of memorization. In this work, we challenge this view and demonstrate that large language models (LLMs) can, in fact, generalize over rote memorized data. We introduce a two-phase “memorize-then-generalize” framework, where the model first rote memorizes factual subject-object associations using a synthetic semantically meaningless key token and then learns to generalize by fine-tuning on a small set of semantically meaningful prompts. Extensive experiments over 8 LLMs show that the models can reinterpret rote memorized data through the semantically meaningful prompts, as evidenced by the emergence of structured, semantically aligned latent representations between the key token and the semantically meaningful prompts. This surprising finding opens the door to both effective and efficient knowledge injection as well as possible risks of repurposing the memorized data for malicious usage.