ADM-v2: Pursuing Full-Horizon Roll-out in Dynamics Models for Offline Policy Learning and Evaluation
{kind=link}
Abstract
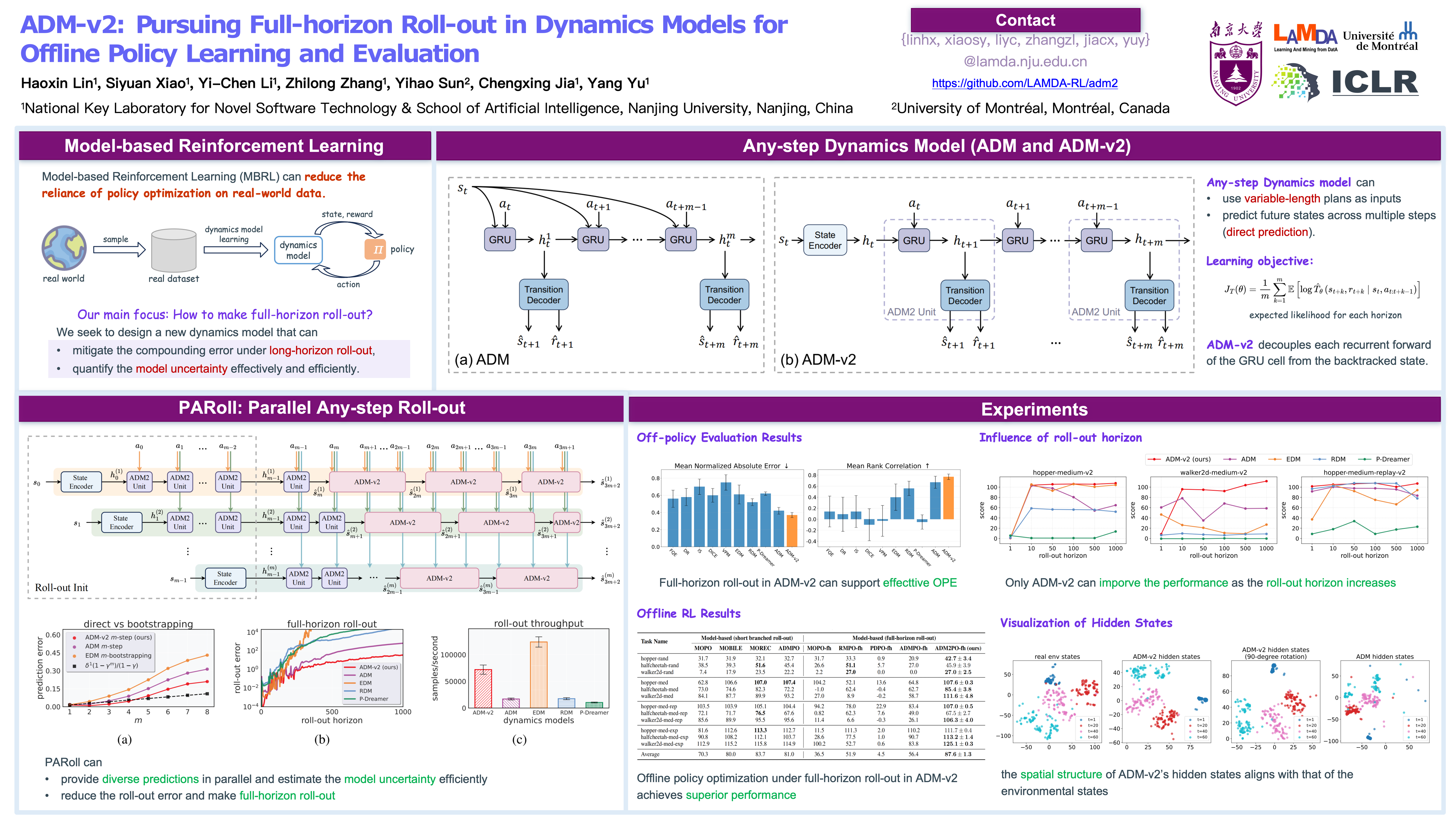
Model-based methods for offline Reinforcement Learning transfer extensive policy exploration and evaluation to data-driven dynamics models, effectively saving real-world samples in the offline setting. We expect the dynamics model to allow the policy to roll out full-horizon episodes, which is crucial for ensuring sufficient exploration and reliable evaluation. However, many previous dynamics models exhibit limited capability in long-horizon prediction. This work follows the paradigm of the Any-step Dynamics Model (ADM) that improves future predictions by reducing bootstrapping prediction to direct prediction. We structurally decouple each recurrent forward of the RNN cell from the backtracked state and propose the second version of ADM (ADM-v2), making the direct prediction more flexible. ADM-v2 not only enhances the accuracy of direct predictions for making full-horizon roll-outs but also supports parallel estimation of the any-step prediction uncertainty to improve efficiency. The results on DOPE validate the reliability of ADM-v2 for policy evaluation. Moreover, via full-horizon roll-out, ADM-v2 for policy optimization enables substantial advancements, whereas other dynamics models degrade due to long-horizon error accumulation. We are the first to achieve SOTA under the full-horizon roll-out setting on both D4RL and NeoRL. The code is available at https://github.com/LAMDA-RL/adm2.