Inlier-Centric Post-Training Quantization for Object Detection Models
{kind=link}
Abstract
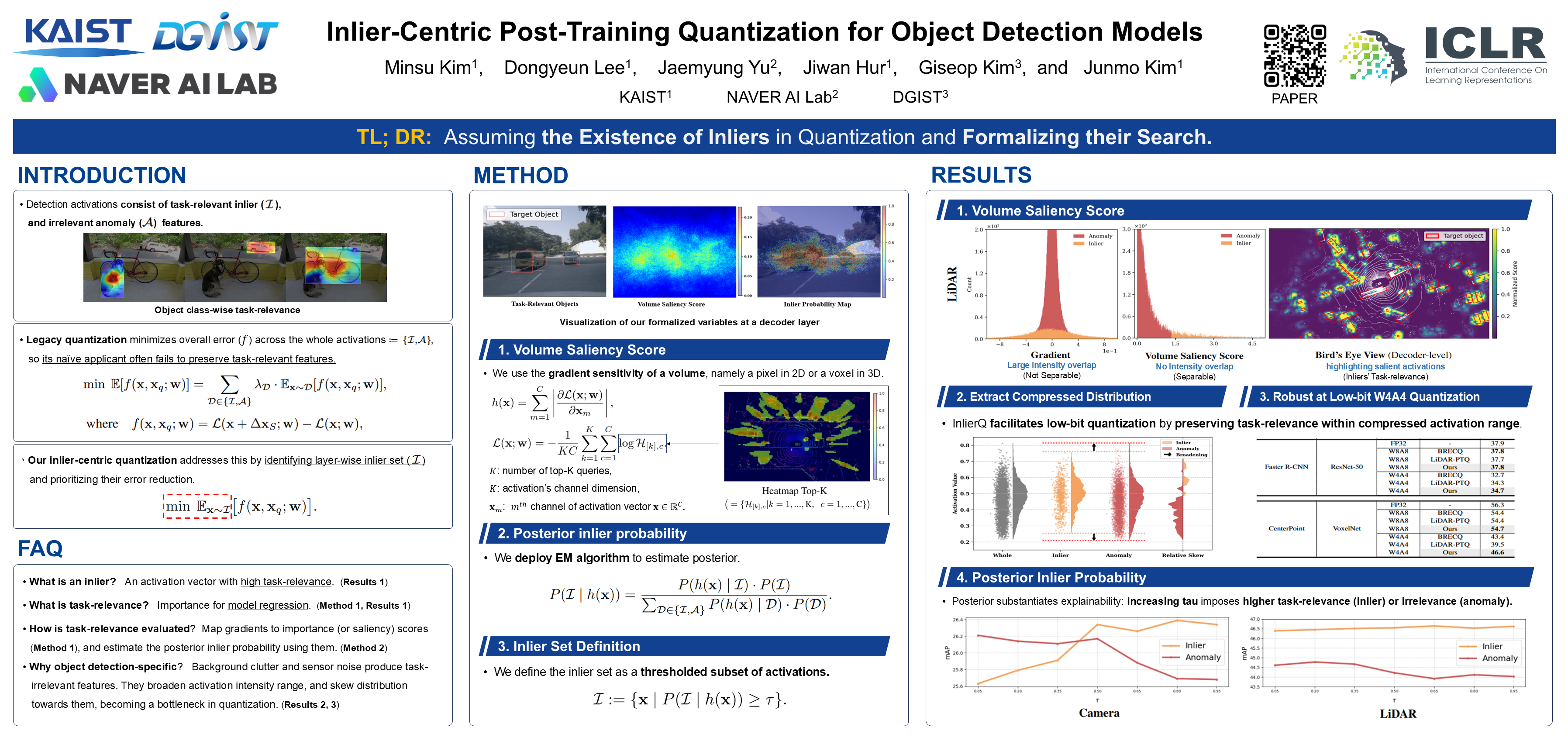
Object detection is pivotal in computer vision, yet its immense computational demands make deployment slow and power-hungry, motivating quantization. However, task-irrelevant morphologies such as background clutter and sensor noise induce redundant activations (or anomalies). These anomalies expand activation ranges and skew activation distributions toward task-irrelevant responses, complicating bit allocation and weakening the preservation of informative features. Without a clear criterion to distinguish anomalies, suppressing them can inadvertently discard useful information. To address this, we present InlierQ, an inlier-centric post-training quantization approach that separates anomalies from informative inliers. InlierQ computes gradient-aware volume saliency scores, classifies each volume as an inlier or anomaly, and fits a posterior distribution over these scores using the Expectation-Maximization (EM) algorithm. This design suppresses anomalies while preserving informative features. InlierQ is label-free, drop-in, and requires only 64 calibration samples. Experiments on the COCO and nuScenes benchmarks show consistent reductions in quantization error for camera-based (2D and 3D) and LiDAR-based (3D) object detection.