Towards Quantization-Aware Training for Ultra-Low-Bit Reasoning LLMs
{kind=link}
Abstract
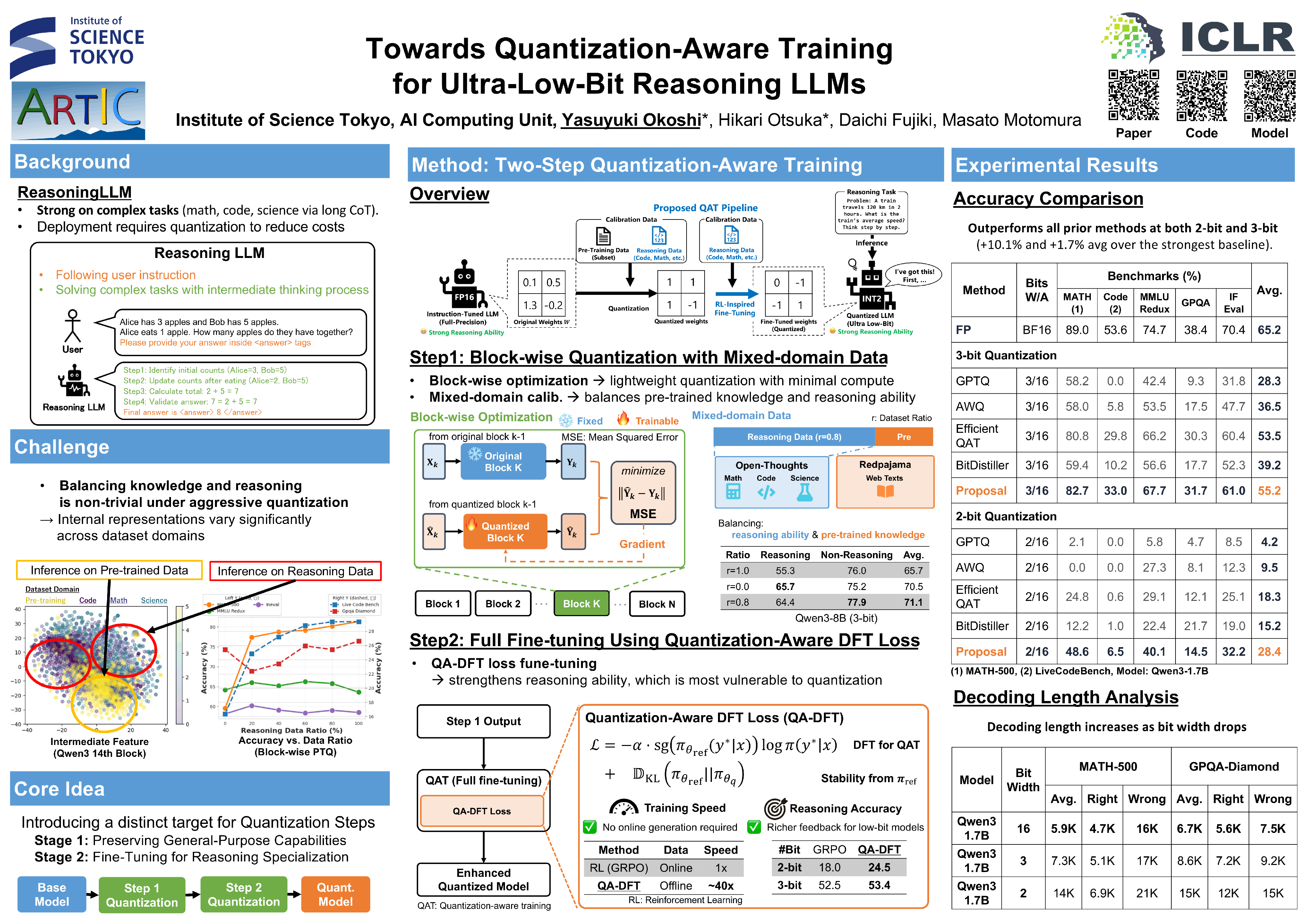
Large language models (LLMs) have achieved remarkable performance across diverse reasoning tasks, yet their deployment is hindered by prohibitive computational and memory costs. Quantization-aware training (QAT) enables ultra-low-bit compression (<4 bits per weight), but existing QAT methods often degrade reasoning capability, partly because complex knowledge structures are introduced during the post-training process in LLMs. In this paper, through a systematic investigation of how quantization affects different data domains, we find that its impact on pre-training and reasoning capabilities differs. Building on this insight, we propose a novel two-stage QAT pipeline specifically designed for reasoning LLMs. In the first stage, we quantize the model using mixed-domain calibration data to preserve essential capabilities across domains; in the second stage, we fine-tune the quantized model with a teacher-guided reward-rectification loss to restore reasoning capability. We first demonstrate that mixed-domain calibration outperforms single-domain calibration by up to 2.74% improvement on average over six tasks, including reasoning and pre-trained tasks. Following experiments on five reasoning benchmarks show that our 2-bit-quantized Qwen3-8B outperforms post-training quantization (PTQ) baselines by 50.45% on average. Moreover, compared to ultra-low-bit-specialized models such as BitNet-2B4T, our pipeline achieves approximately 2\% higher mathematical-reasoning accuracy with fewer than 1B tokens. Code is available: https://github.com/yasu0001/ReasoningQAT