LLMs are Single-threaded Reasoners: Demystifying the Working Mechanism of Soft Thinking
Junhong Wu ⋅ Jinliang Lu ⋅ Zixuan Ren ⋅ Gangqiang Hu ⋅ Zhi Wu ⋅ Dai Dai ⋅ hua wu
{kind=link}
Abstract
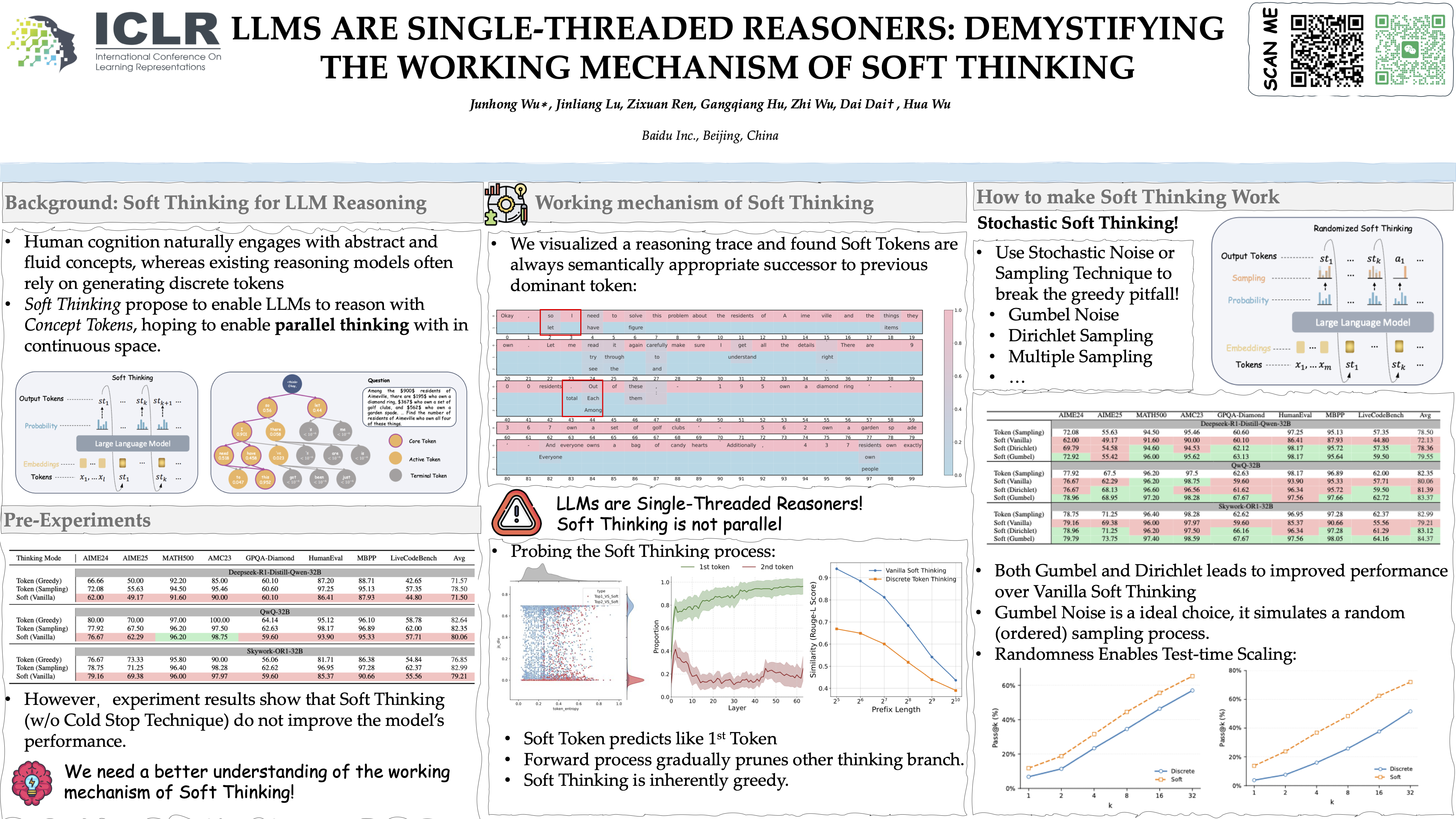
Human cognition naturally engages with abstract and fluid concepts, whereas existing reasoning models often rely on generating discrete tokens, potentially constraining their expressive capabilities. Recent advancements aim to address this limitation by enabling large language models (LLMs) to generate soft, abstract tokens, thus facilitating reasoning within a continuous concept space. In this paper, we investigate the $\textit{Soft Thinking}$ capabilities of various LLMs through a systematic analysis of their internal behavior using a suite of probing techniques. Contrary to the prevailing belief that Soft Thinking supports parallel exploration of diverse reasoning paths, our findings reveal that $\textbf{LLMs behave as single-threaded reasoners}$—they predominantly rely on the token with the highest probability in the soft input to predict the next step. This behavior induces a greedy feedback loop that suppresses alternative reasoning paths and undermines the benefits of transmitting richer information via Soft Tokens. To address this $\textit{Greedy Pitfall}$, we propose $\textbf{Stochastic Soft Thinking}$, which introduces stochasticity to break free from the greedy tendency. Our experiments demonstrate that incorporating $\textit{randomness}$—particularly with the $\textbf{Gumbel-Softmax trick}$—can alleviate the limitations of vanilla approaches and unleash the potential of Soft Thinking, resulting in superior performance across eight reasoning benchmarks.
Video
Chat is not available.
Successful Page Load