POEMetric: The Last Stanza of Humanity
{kind=link}
Abstract
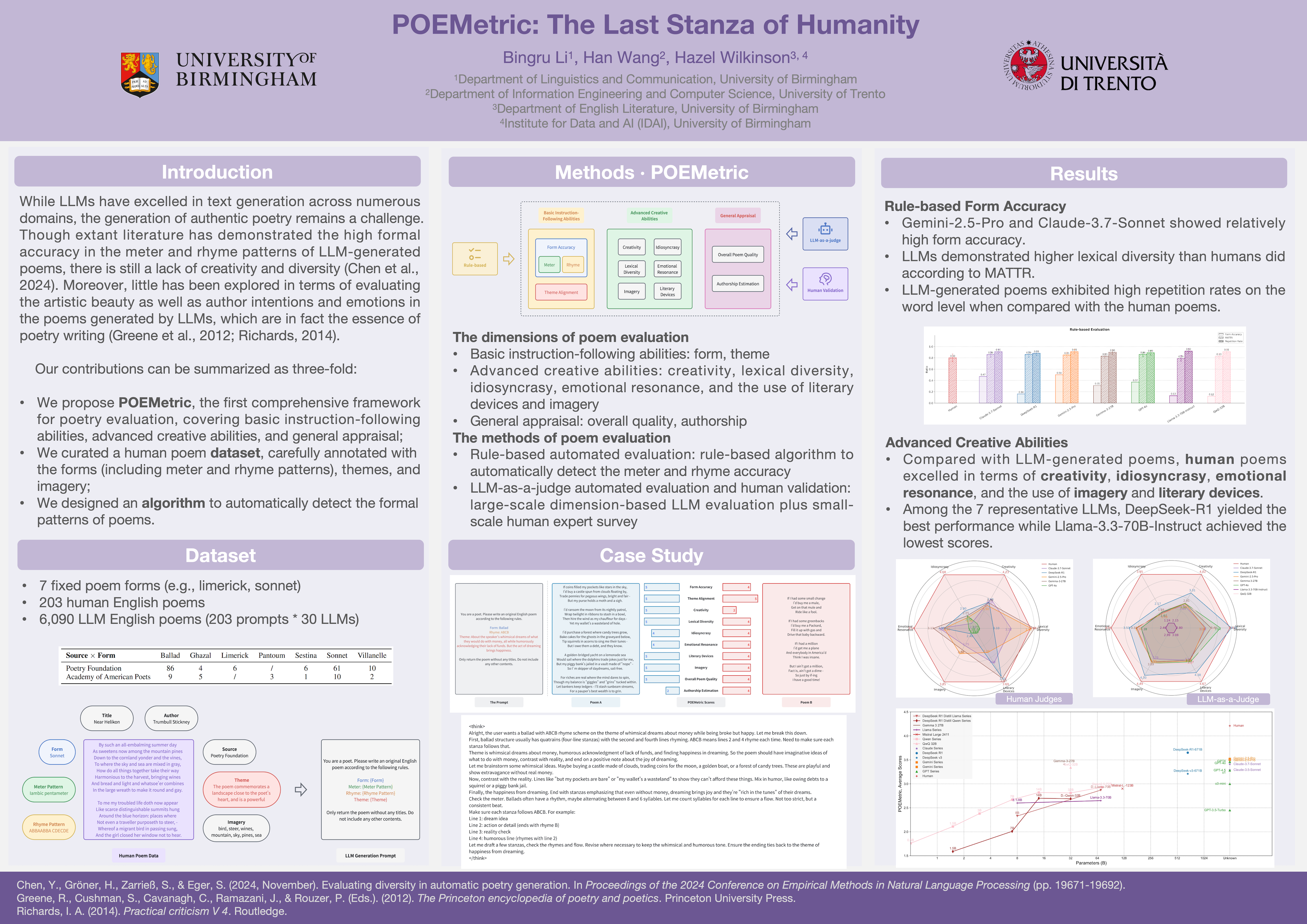
Large Language Models (LLMs) can compose poetry, but how far are they from human poets? In this paper, we introduce POEMetric, the first comprehensive framework for poetry evaluation, examining 1) basic instruction-following abilities in generating poems according to a certain form and theme, 2) advanced abilities of showing creativity, lexical diversity, and idiosyncrasy, evoking emotional resonance, and using imagery and literary devices, and 3) general appraisal of the overall poem quality and estimation of authorship. We curated a human poem dataset - 203 English poems of 7 fixed forms annotated with meter, rhyme patterns and themes - and experimented with 30 LLMs for poetry generation based on the same forms and themes of the human data, totaling 6,090 LLM poems. Based on POEMetric, we assessed the performance of both human poets and LLMs through rule-based evaluation and LLM-as-a-judge, whose results were validated by human experts. Results show that, though the top model achieved high form accuracy (4.26 out of 5.00, with Gemini-2.5-Pro as a judge; same below) and theme alignment (4.99), all models failed to reach the same level of advanced abilities as human poets, who achieved unparalleled creativity (4.02), idiosyncrasy (3.95), emotional resonance (4.06), and skillful use of imagery (4.49) and literary devices (4.67). Humans also defeated the best-performing LLM in overall poem quality (4.22 vs. 3.20). As such, poetry generation remains a formidable challenge for LLMs.