DUET: Optimizing LLM Training Data Mixtures via Noisy Feedback from Unseen, Downstream Evaluation Tasks
{kind=link}
Abstract
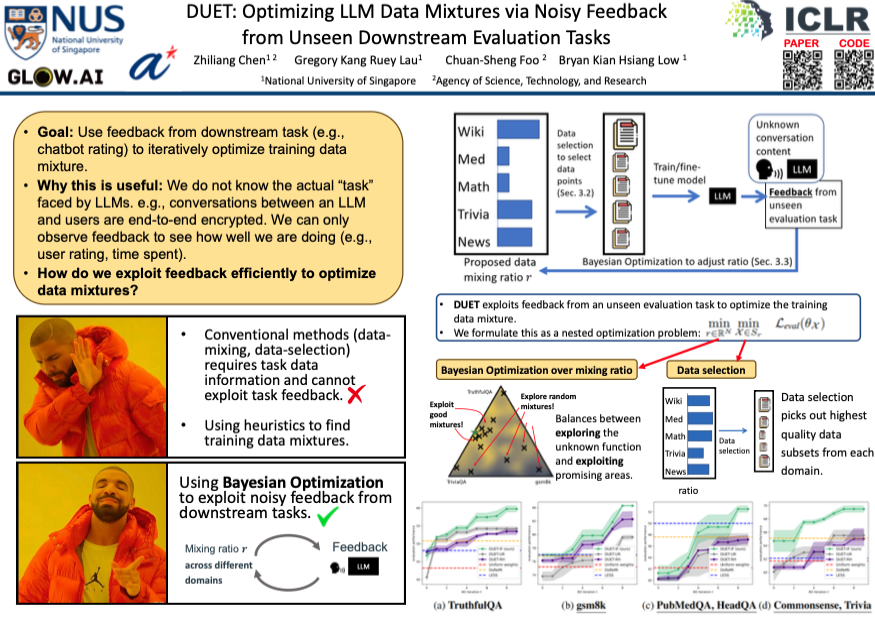
The performance of an LLM depends heavily on how well the training data matches the downstream evaluation task. However, in many practical settings, we typically do not know the data in the evaluation task (e.g., conversations between a chatbot and users are end-to-end encrypted). We refer to such tasks as unseen evaluation tasks. We can only deploy the LLM on these unseen evaluation tasks to gather multiple rounds of feedback on how well the model performs (e.g., gathering user ratings from a chatbot). In addition, this feedback can be noisy. How can we exploit such noisy feedback efficiently to optimize the LLM training data-mixture? Our paper presents DUET, a novel global-to-local algorithm that optimizes training data mixtures by interleaving data selection with Bayesian optimization to exploit coarse and noisy feedback from a downstream evaluation task. DUET is flexible enough to incorporate different data selection methods, each with different performance-compute tradeoffs. By analyzing DUET's cumulative regret, we theoretically show that DUET converges to the optimal training data mixture even without any fine-grained data information from an unseen task. Finally, our experiments across a variety of language tasks demonstrate that DUET attains substantial performance improvements over existing data selection and mixing methods in the unseen-task setting. Our library, which is flexible enough to optimize different LLM training ingredients, can be found at https://github.com/chenzhiliang94/BO-for-LLM.