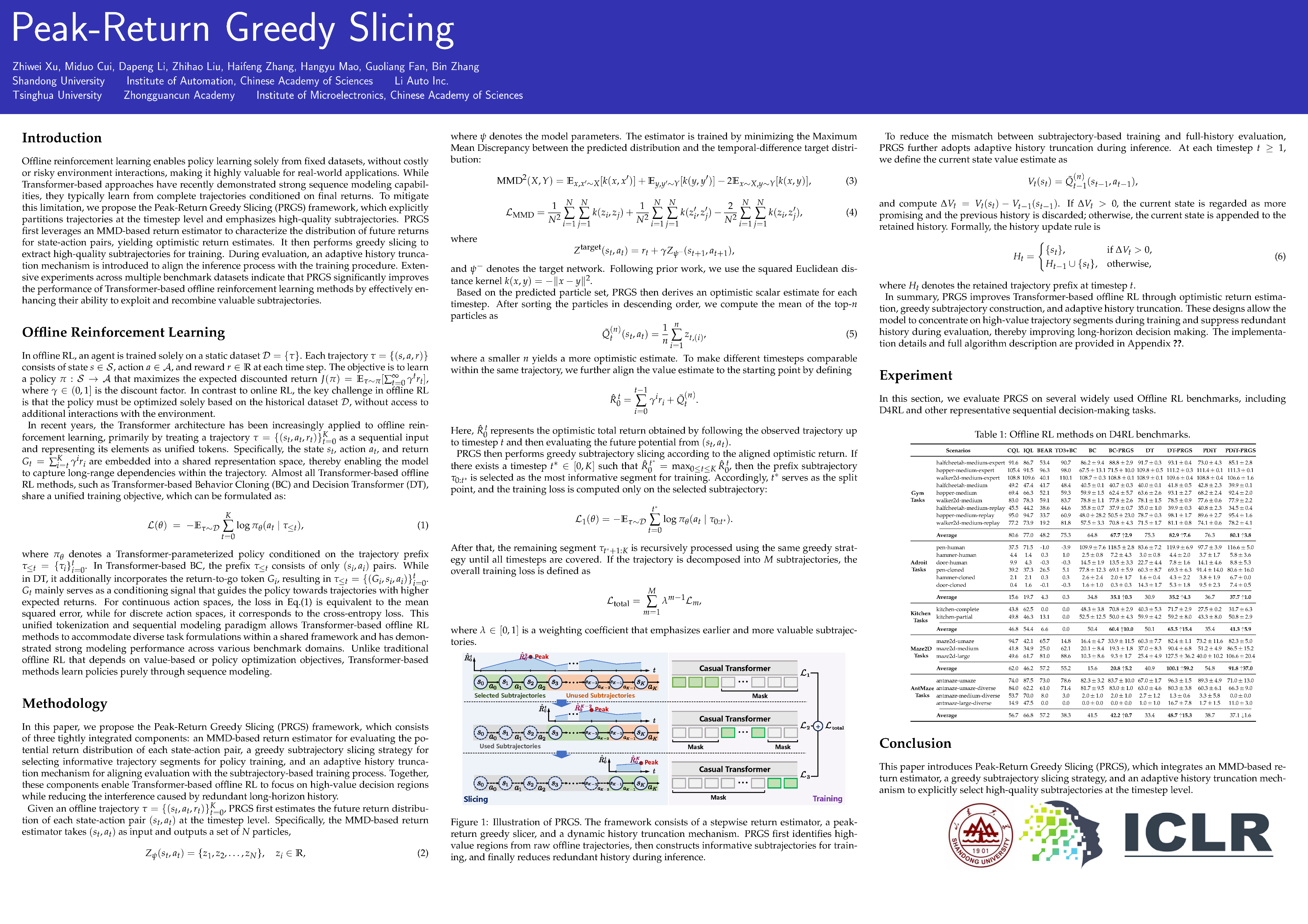
Peak-Return Greedy Slicing: Subtrajectory Selection for Transformer-based Offline RL
{kind=link}
Abstract
Offline reinforcement learning enables policy learning solely from fixed datasets, without costly or risky environment interactions, making it highly valuable for real-world applications. While Transformer-based approaches have recently demonstrated strong sequence modeling capabilities, they typically learn from complete trajectories conditioned on final returns. To mitigate this limitation, we propose the Peak-Return Greedy Slicing (PRGS) framework, which explicitly partitions trajectories at the timestep level and emphasizes high-quality subtrajectories. PRGS first leverages an MMD-based return estimator to characterize the distribution of future returns for state-action pairs, yielding optimistic return estimates. It then performs greedy slicing to extract high-quality subtrajectories for training. During evaluation, an adaptive history truncation mechanism is introduced to align the inference process with the training procedure. Extensive experiments across multiple benchmark datasets indicate that PRGS significantly improves the performance of Transformer-based offline reinforcement learning methods by effectively enhancing their ability to exploit and recombine valuable subtrajectories.