A Comprehensive Information-Decomposition Analysis of Large Vision-Language Models
{kind=link}
Abstract
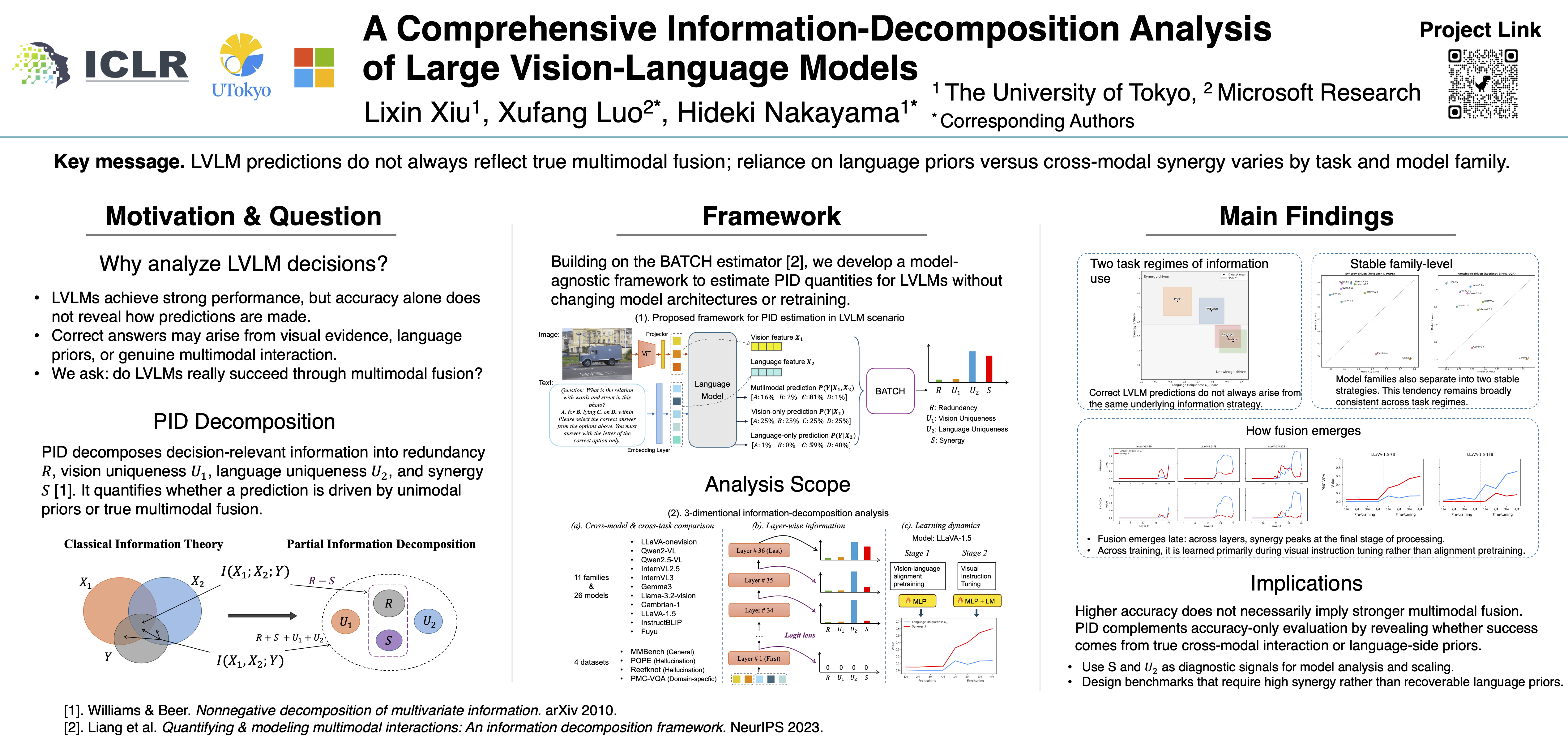
Large vision-language models (LVLMs) achieve impressive performance, yet their internal decision-making processes remain opaque, making it difficult to determine if the success stems from true multimodal fusion or from reliance on unimodal priors. To address this attribution gap, we introduce a novel framework using partial information decomposition (PID) to quantitatively measure the ``information spectrum'' of LVLMs---decomposing a model's decision-relevant information into redundant, unique, and synergistic components. By adapting a scalable estimator to modern LVLM outputs, our model-agnostic pipeline profiles 26 LVLMs on four datasets across three dimensions---\emph{breadth} (cross-model & cross-task), \emph{depth} (layer-wise information dynamics), and \emph{time} (learning dynamics across training). Our analysis reveals two key results: (i) two task regimes (synergy-driven vs.\ knowledge-driven) and (ii) two stable, contrasting family-level strategies (fusion-centric vs.\ language-centric). We also uncover a consistent three-phase pattern in layer-wise processing and identify visual instruction tuning as the key stage where fusion is learned. Together, these contributions provide a quantitative lens beyond accuracy-only evaluation and offer insights for analyzing and designing the next generation of LVLMs. Code and data are available at \url{https://github.com/RiiShin/pid-lvlm-analysis}.