LinearSR: Unlocking Linear Attention for Stable and Efficient Image Super-Resolution
Xiaohui Li ⋅ Shaobin Zhuang ⋅ Shuo Cao ⋅ Yang Yang ⋅ Yuandong Pu ⋅ Qi Qin ⋅ Siqi Luo ⋅ Bin Fu ⋅ Yihao Liu
{kind=link}
Abstract
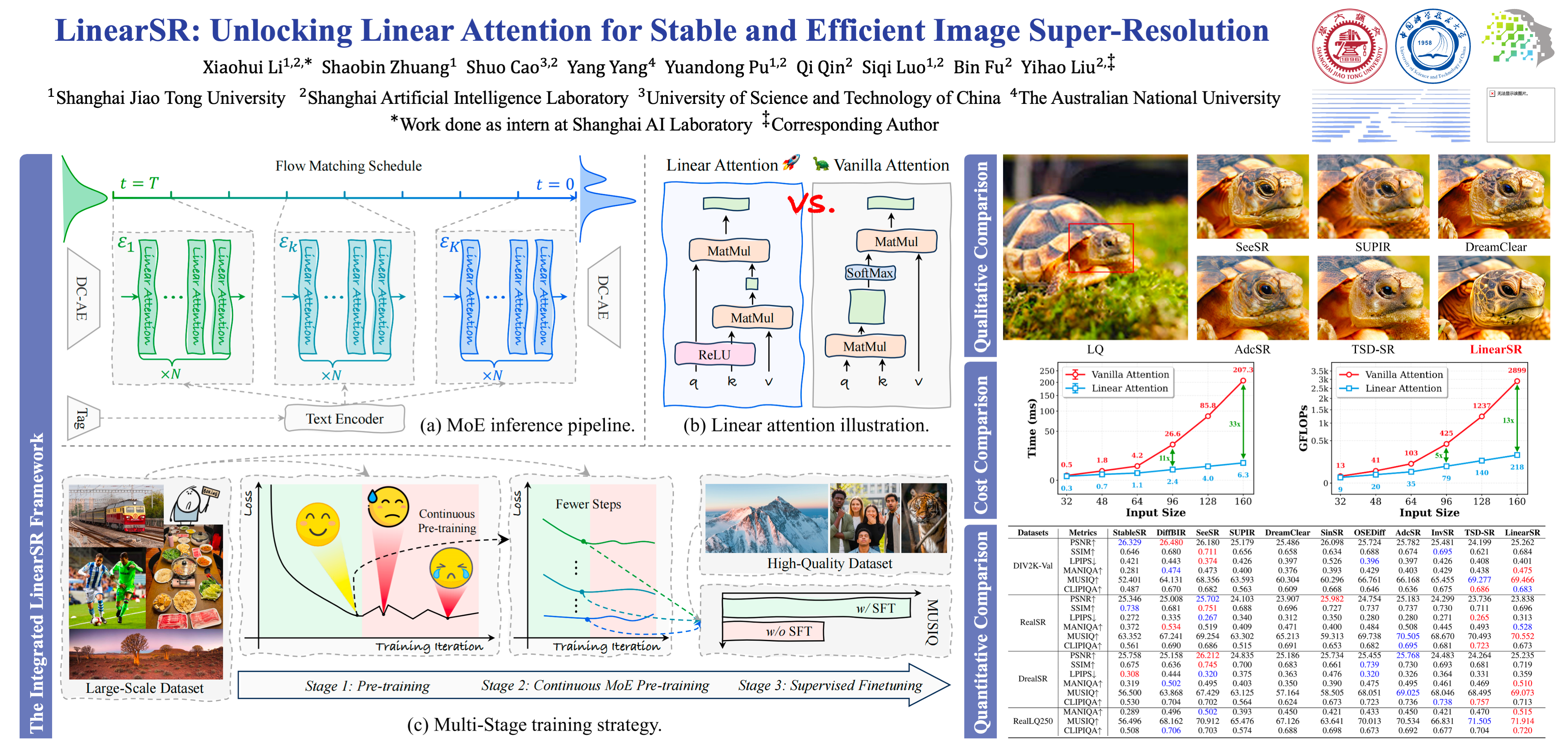
Generative models for Image Super-Resolution (SR) are increasingly powerful, yet their reliance on self-attention's quadratic complexity ($O(N^2)$) creates a major computational bottleneck. Linear Attention offers an $O(N)$ solution, but its promise for photorealistic SR has remained largely untapped, historically hindered by a cascade of interrelated and previously unsolved challenges. This paper introduces LinearSR, a holistic framework that, for the first time, systematically overcomes these critical hurdles. Specifically, we resolve a fundamental, training instability that causes catastrophic model divergence using our novel ''knee point''-based Early-Stopping Guided Fine-tuning (ESGF) strategy. Furthermore, we mitigate the classic perception-distortion trade-off with a dedicated SNR-based Mixture of Experts (MoE) architecture. Finally, we establish an effective and lightweight guidance paradigm, TAG, derived from our ''precision-over-volume'' principle. Our resulting LinearSR model simultaneously delivers state-of-the-art perceptual quality with exceptional efficiency. Its core diffusion forward pass (1-NFE) achieves SOTA-level speed, while its overall multi-step inference time remains highly competitive. This work provides the first robust methodology for applying Linear Attention in the photorealistic SR domain, establishing a foundational paradigm for future research in efficient generative super-resolution.
Video
Chat is not available.
Successful Page Load