MICLIP: Learning to Interpret Representation in Vision Models
{kind=link}
Abstract
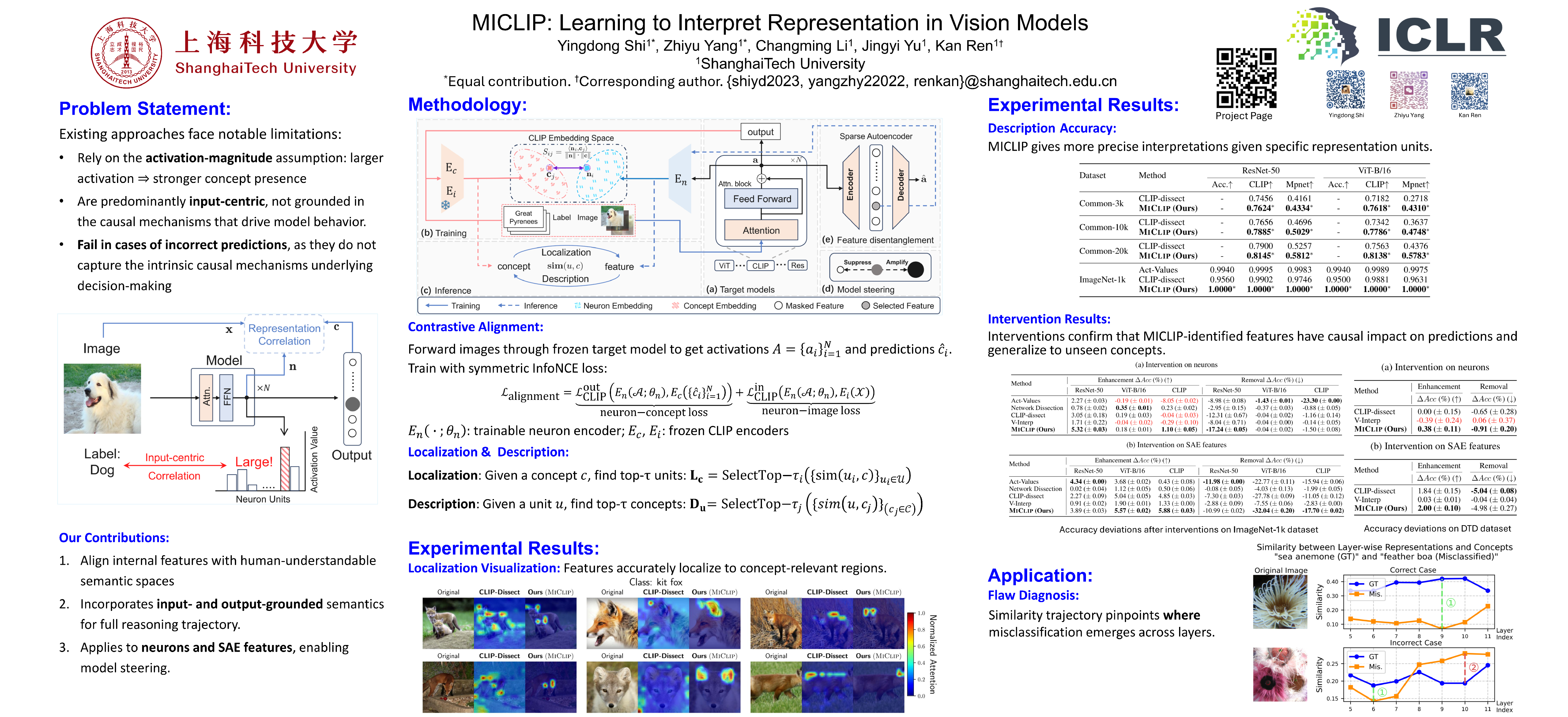
Vision models have demonstrated remarkable capabilities, yet their decision-making processes remain largely opaque. Mechanistic interpretability (MI) offers a promising avenue to decode these internal workings. However, existing interpretation methods suffer from two key limitations. First, they rely on the flawed activation-magnitude assumption, assuming that the importance of a neuron is directly reflected by the magnitude of its activation, which ignores more nuanced causal roles. Second, they are predominantly input-centric, failing to capture the causal mechanisms that drive a model's output. These shortcomings lead to inaccurate and unreliable internal representation interpretations, especially in cases of incorrect predictions. We propose MICLIP (Mechanism-Interpretability via Contrastive Learning), a novel framework that extends CLIP’s contrastive learning to align internal mechanisms of vision models with general semantic concepts, enabling interpretable and controllable representations. Our approach circumvents previous limitations by performing multimodal alignment between a model's internal representations and both its input concepts and output semantics via contrastive learning. We demonstrate that MICLIP is a general framework applicable to diverse representation unit types, including individual neurons and sparse autoencoder (SAE) features. By enabling precise, causal-aware interpretation, MICLIP not only reveals the semantic properties of a model's internals but also paves the way for effective and targeted manipulation of model behaviors.